Redis(八) 管道机制
1.工作原理
在使用Redis客户端发送请求命令时,每条命令都会与Redis服务端进行一次socket通信,那么每次请求的耗时等于服务端处理时间+网络传输时间(三次握手、四次挥手)。服务端的操作都是在内存中进行,不会耗费太多的时间,因此一个请求的耗时很大程度取决于网络开销。管道技术就是为了批量操作场景下,通过减少服务端与客户端的通信次数,减少请求耗时的一种优化。
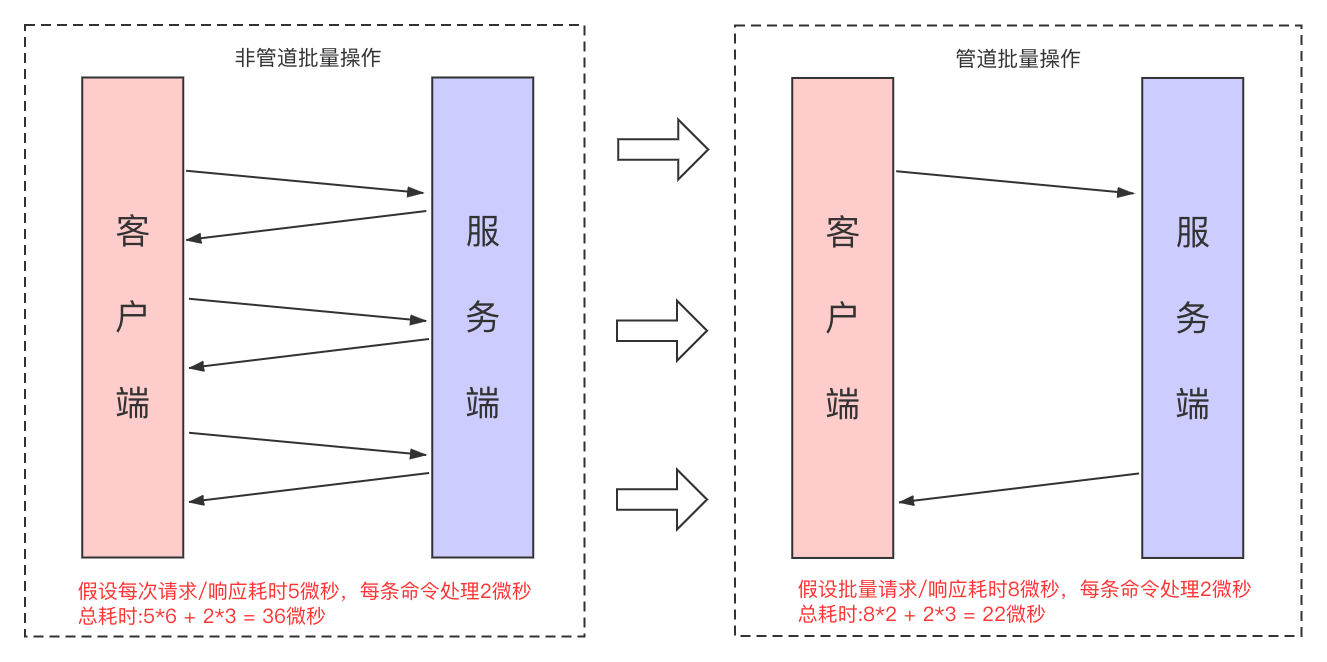
图中可以看出pipeline就是为了批量操作而设计的,三条命令使用管道没什么直观效果,但随着命令数量的增加或网络延迟变高,管道操作的优势会越来越明显。
2.客户端命令
对于服务端来说就没有pipeline相关概念,这完全属于客户端支持的功能,服务端无法区分请求是否为pipeline请求,只是支持一次通信多条命令的的接收,最终还是单条执行完后汇总返回。另外pipeline请求会独占链接,期间不能进行非pipeline请求,因此使用pipeline需要单独分配连接对象。
客户端代码:
1 | List<Long> List = redisTemplate.executePipelined(new RedisCallback<Long>() { |
3.命令行限制
虽然pipeline是为批量操作而设计的,明面上没有任何数量限制,但这并不代表你可以在请求中无限制添加命令,每个socket在操作系统内核中都有一个发送缓冲区和一个接收缓冲区,pipeline命令处理完毕后将数据发送到接收缓冲区一直保存,直到应用程序(客户端)读走为止。如果pipeline命令返回的数据过多导致接收缓冲区存满,根据TCP socket原理会发送信息给服务端告知接收窗口关闭,保证TCP套接口接收缓冲区不会溢出,从而保证了TCP是可靠传输。那么剩余未发送的结果数据会直接丢弃。
注: 官方建议每次pipeline请求不要超过1W条命令
4.适用场景
- pipeline请求发送后客户端需同步阻塞等待结果,适用对响应实时性要求不高的场景
- pipeline请求不可能保证所有的命令都执行成功,适用那些允许一定比例失败的场景
- pipeline请求不能保证多条命令的原子性,适用没有执行关系的命令集场景