Redis(一) 常用数据类型
1.字符串(string)
string是Redis最基础的数据类型,底层通过int或SDS(动态字符串:Simple Dynamic String)实现。在设置一个字符串键值对后,Redis会根据value的类型、长度来决定使用哪种编码,通过不同的编码方式映射到不同的数据结构。
1.1 内部结构
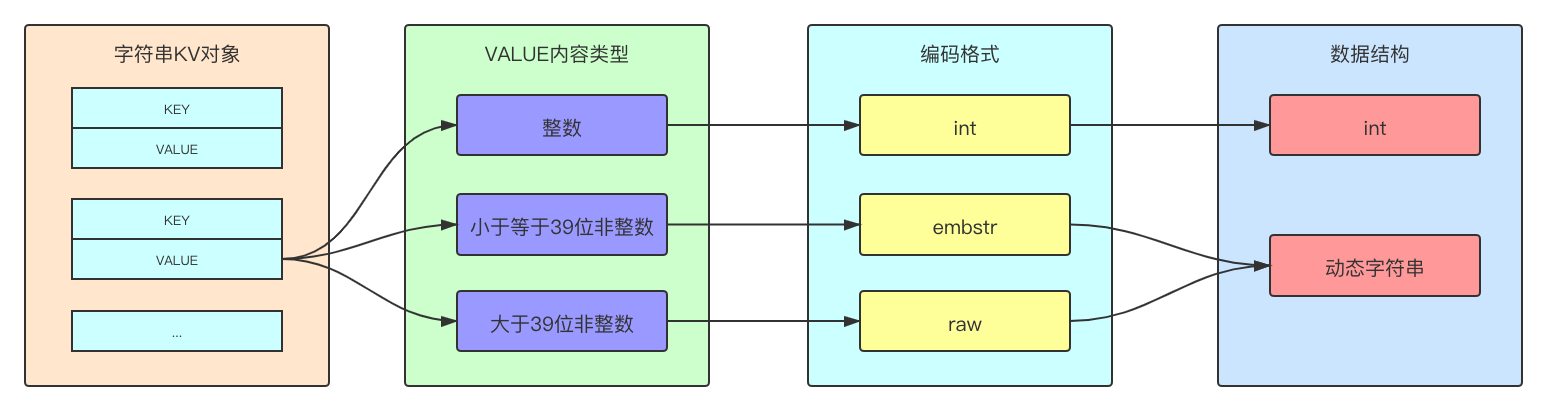
int类型数据结构支持incr、incrby、decr、decrby等命令对value值进行增减操作。
embstr编码的SDS结构是专门用于保存短字符串的优化编码方式,与raw编码不同,embstr编码通过一次内存分配函数将字符串KV对象和value值分配在连续的内存块中,提高CPU取数据的效率问题。
raw编码的SDS结构用于存储较长的字符串,通过俩次内存分配函数得到俩块内存,给字符串KV对象和value分别存储。
1.2 常用命令
1 | get [key] [value] // 获取指定key对应value |
1.3 应用场景
- 分布式缓存: 字典常量数据、JSON字符串、图片视频等序列化数组、Session等
- 分布式锁: 根据业务对接口或代码块加分布式锁
- 常规计数: 网站浏览量、点击量、收藏量等
- 接口监控: 通过AOP和Redis计数器对指定接口限流或屏蔽
2 哈希(hash)
hash类型在Redis类型中是指键值中的值本身又是一个键值对,底层通过ziplist(压缩列表)或hashtable(哈希表)实现,Redis会根据哈希表中的KV元素数量、每个元素值大小来决定使用哪种数据。
2.1 内部结构
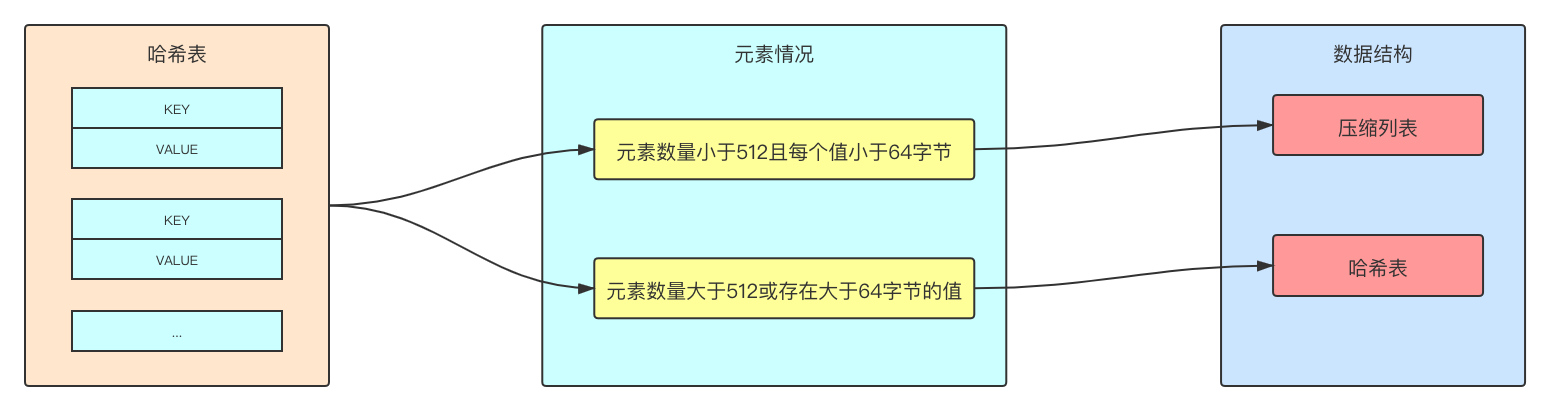
ziplist是Redis自己设计的数据结构,使用更加紧凑的结构实现多个元素的连续存储,相比较hashtable更加节约内存,但是在大量元素的情况下读写效率不如hashtable,大块连续的存储空间的要求也比较苛刻。
hashtable的结构与Java JDK1.7版本的HashMap类似,采用数组加链表的形式进行存储,相比较ziplist在大量元素情况下读写效率更好,因为读写时间复杂度为O(1)。
2.2 常用命令
1 | hset [object-key] [hash-key] [hash-value] // 对某个hash对象设置单个键值对 |
2.3 应用场景
哈希一般用于存储结构简单、属性较多、修改频率较高的对象信息,比如购物车、商品信息、配置信息等。哈希存储对象相对于字符串存储对象的优势在于,整个修改操作可以只针对某个属性。
比如购物车的商品数量发生改变,字符串存储需要将内容提取出来转为对象,修改完属性后在转化为字符串存储,在购物车数据比较大的情况下会增加很多无意义的资源浪费。哈希类型存储购物车信息一般将每个商品的ID和数量作为元素的键值对,每次发生改变也仅仅是修改某个键值对的value,涉及到的资源消耗相对较少。
3.列表(list)
list类型是用来存储多个有序的字符串,3.2之前的版本底层通过ziplist(压缩列表)或linkedlist(链表)实现,Redis会根据列表中的KV元素数量、每个元素值大小来决定使用哪种数据结构,3.2包括以后版本采用quicklist代替。
3.1 内部结构
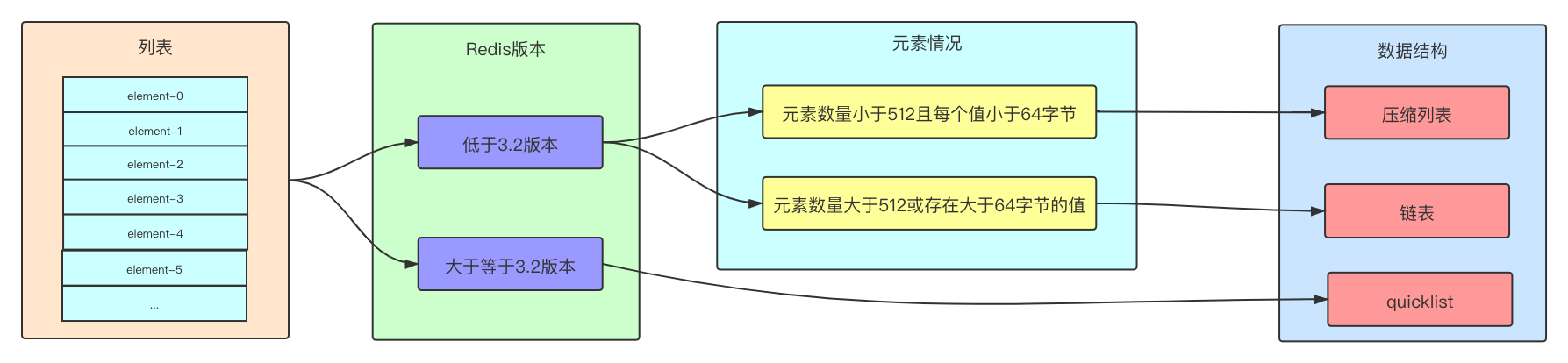
- ziplist的优缺点上面已经提到了。
- linkedlist和ziplist都是线性数据结构,当元素较多或者某元素内存占用较大时,连续存储不太现实,还得采用linkedlist方式进行存储。
3.2 应用场景
1 | lpush [key] [value] [value]... // 在list的头部插入单个或多个value,如果可以不存在则先创建(返回插入个数) |
3.3 应用场景
Redis关于此类型结构的操作比较丰富,支持两端插入和弹出、还可以获取指定范围的元素列表、获取指定索引下标的元素等,是一个比较灵活的数据结构,因此应用场景也比较灵活。可以利用list实现消息队列、列表的分页数据缓存等。
4.去重集合(set)
set类型是一个无序并唯一的键值集合,底层通过inset(整数集合)或hashtable(哈希表)实现,根据集合内部的元素类型、个数来决定使用哪种数据结构。
4.1 内部结构
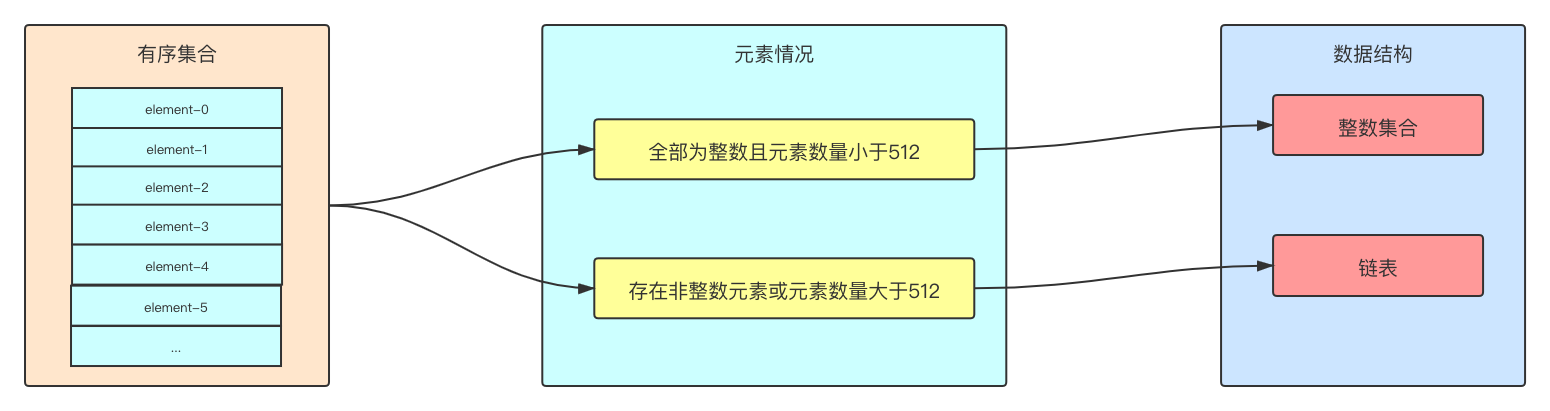
intset集合存在的意义就是尽量减少内存的使用,当intset的条件无法满足时,使用hashtable进行存储,set集合对hashtable的使用和Java一样,仅仅使用key而已。
4.2 常用命令
1 | sadd [key] [value-1] [value-2]... // 添加单个或多个元素 |
4.3 应用场景
set类型具有无序、不可重复、支持并交差等特性,在电商、社交、视频网站等平台有着广泛的应用,通过将用户的标签信息存储在set结构中,可以向用户推荐相同兴趣爱好的好友,或者存储好友信息来展示相同好友功能等。
通过set集合提供的SADD、SRANDMEMBER命令可以实现抽奖功能。需要注意的是Redis在2.6版本才支持SADD命令的count参数,在3.2版本支持SRANDMEMBER命令的count参数,2.6版本以下仅支持单次获取一个随机元素。
5.有序去重集合(zset)
zset类型相对于set类型,每个元素多了一个score值,保证元素内容不重复的前提下,通过score值对元素自动排序,底层通过ziplist(压缩列表)或skiplist(跳跃表)实现,根据集合内部的元素个数、大小来决定使用哪种数据结构。
5.1 数据结构
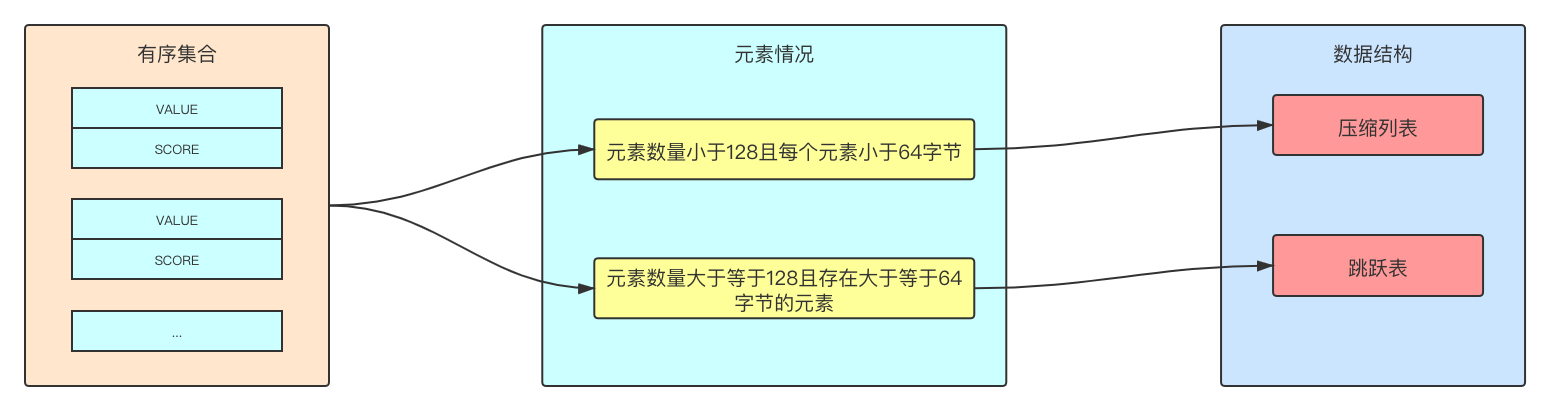
- ziplist的优缺点上面已经提到了。
- skiplist也是一个有序的数据结构,为了避免链表结构这种查找元素需要从头到尾遍历的弊端,采用在每个节点中维持多个指向其他节点的指针,从而达到快速访问节点的目的。
- zset还会维护一个字典结构(hashtable),用于新增元素时判断是否已存在
5.2 常用命令
1 | zadd [key] [score-1] [value-1] [score-2] [value-2]... // 添加单个或多个元素 |
5.3 应用场景
既然数据结构的亮点是排序,那么应用场景自然也是和排序相关。应用最为广泛的就是排行榜系统,例如某个网站的文章访问量、视频播放量/点赞量、电商系统商品的销售量等等。
Redis的ZRANGEBYLEX命令支持对相同的score元素进行排序,实现方式是将元素字符串转化为二进制数组的字节数进行比较,因此可以用来实现手机号、姓名等排序场景。
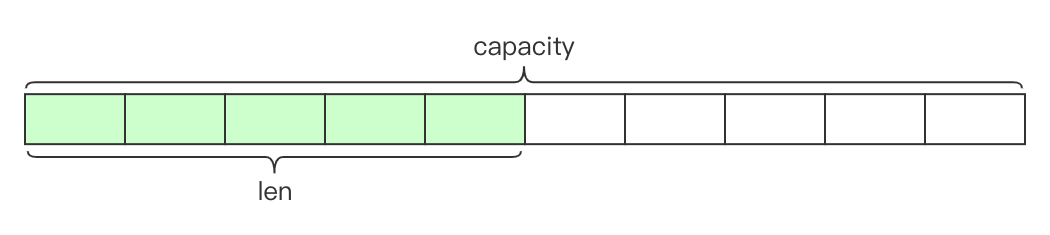
6.SDS(动态字符串)
SDS的实现原理和Java的ArrayList差不多,都是采用动态扩容的方式来减少内存的频繁分配。当字符串长度小于1M时,扩容后为原来的两倍,当字符串超过1M时,每次固定扩容1M。Redis对SDS的扩容限制为最高512M,也就是说Redis的字符串最多可以存储512M的字符串,超过此容量会报错。
6.1 内部结构
7.ziplist(压缩列表)
ziplist存在的意义就是压缩、节约内存,当然这种节约内存是相对于数组而言进行的优化,在Redis中存在的意义是为了弥补链表和哈希表在内存分配上的不足。
7.1 数组存储的弊端
我们都知道数组中每个元素的大小相同,在我们存储字符串的时候,不能保证存储的每个元素大小都相同,这就需要以占用内存最大的元素作为数组元素大小的标准。假设某个数组中最大的元素占用30KB,数组中小于30KB的元素存储就会出现部分下标的内存浪费:
7.2 数组压缩存储
数组的优势在于分配一片连续的空间,提升CPU的内存访问效率,压缩列表保留了这个优势,同时在结构上将每个下标的进行压缩,压缩后的占用保持和对应元素大小一致,达到节约内存的目的:
这就有个问题了,每个元素占用的内存块不固定,无法向数组那样通过下标内存大小计算出下个元素的位置。因此压缩列表为每个元素添加了一个length属性,通过这个属性就很容易计算出下个元素的位置并提取数据了:
7.2 优缺点
ziplist的特点是数据在内存中连续存储,不会像linkedlist、hashtable那样分散存储,不需要额外的存储指针来管理分散内存块之间的关联,再加上ziplist内存块中绝大多数空间都用来存储元素数据,且元素数据不会浪费内存空间,因此ziplist的优势在于节约内存。
当元素数量上升,或某个元素占用内存过大,会导致当前内存块大小无法满足而必须要扩展,内存块越大扩展的消耗就越大。对于list类型来说,提供的常用命令都是对列表的增删操作,大量元素下的情况下linkedlist更能胜任。对于hash类型来说,无论元素数量多大查询某个元素的时间复杂度永远是O(1),也比ziplist的更合适。
8.quicklist(压缩列表+链表混合)
列表类型在Redis3.2版本以前采用ziplist和linkedlist进行存储,前者的思想是时间换空间,后者的思想是空间换时间,无论哪种都有很明显的优缺点为此Redis3.2版本开始对列表数据结构进行了改造,创建了quicklist代替ziplist和linkedlist。
8.1 内存结构
quicklist是ziplist和linkedlist的混合体,从宏观上讲仍然是一个linkedlist,而其中的每个元素都是一个zipList,zipList内部紧凑且连续的存储着真实的元素数据: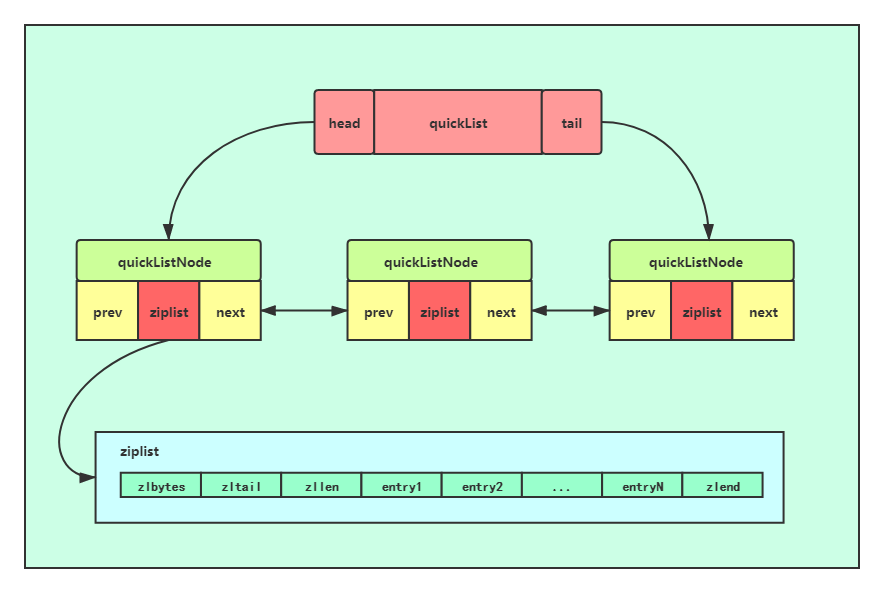
8.1 新增节点过程
quicklist仍然是将元素存储在zipList中,上面也讲过zipList不适合存储大型字符串和大量元素,扩容是他的硬伤。当新插入的元素无法放入zipList中时,quicklist会直接创建一个新的zipList并将数据存入,然后将新创建的zipList作为一个元素添到linkedlist中,删除也是同样的道理。
9.skiplist(跳表)
对于链表来说,即使结构中的数据是有序存储,如果想要查询某个数据也只能从头到尾遍历,查询效率较低。skiplist也是一种有序链表,为了提高查询效率,skiplist在每个节点上建立索引,避免从头到尾遍历,是一种空间换时间的优化思想。
9.1 内部结构
传统链表获取第9个元素,需要通过指针地址查询9次: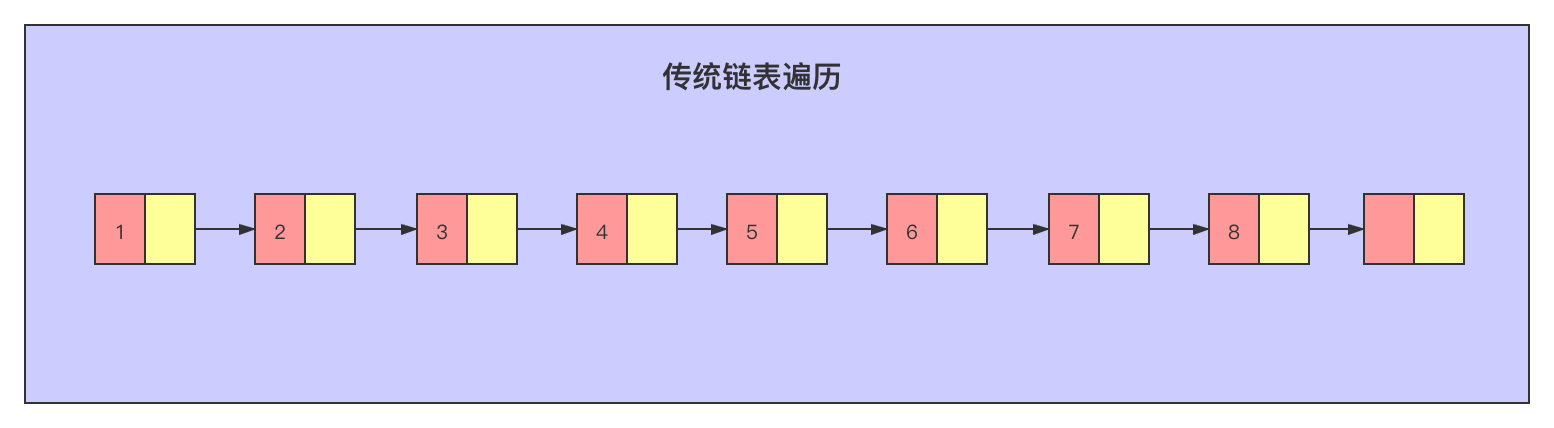
跳表获取第9个元素,通过元素存储的索引,只需要通过指针地址查询5次: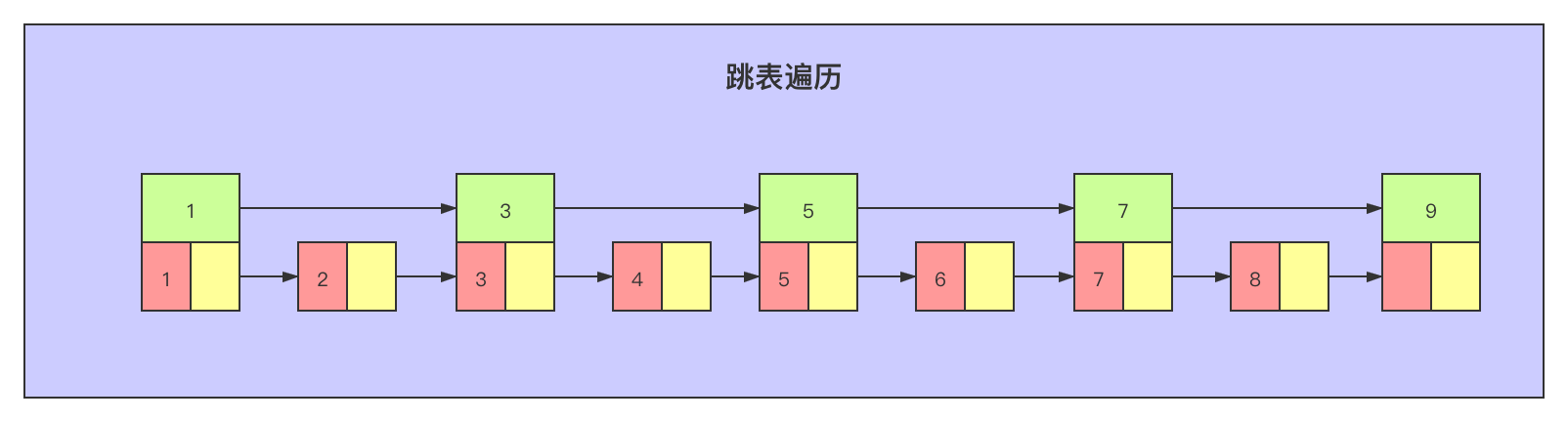
如果获取的是第8个元素,则通过索引遍历到索引9(大于8),然后退回索引7向后遍历: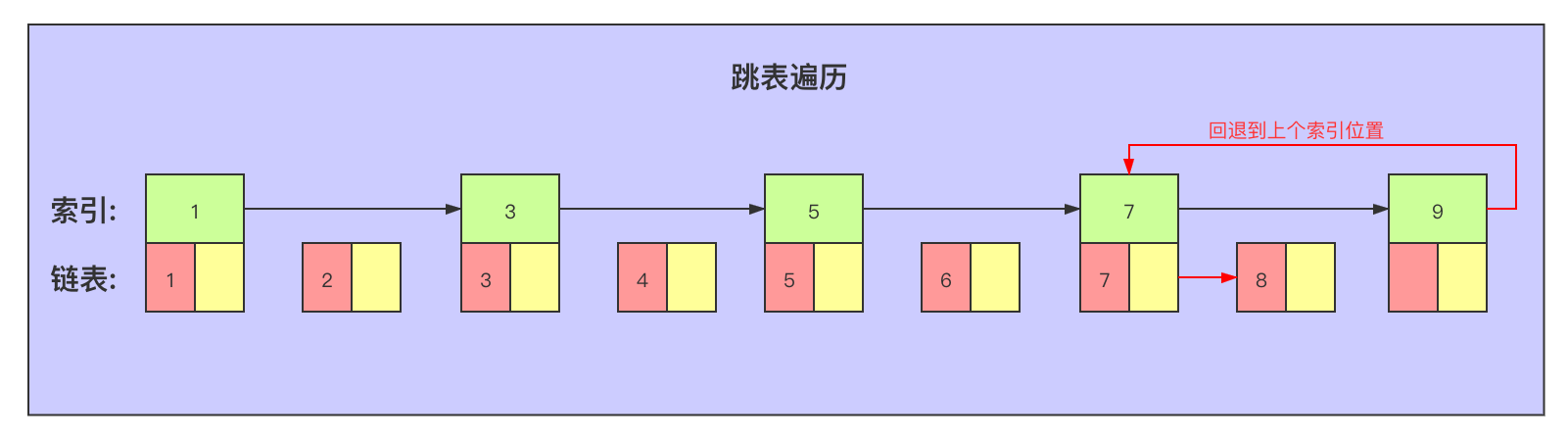
当元素数量增多,可以建立多层索引提高效率: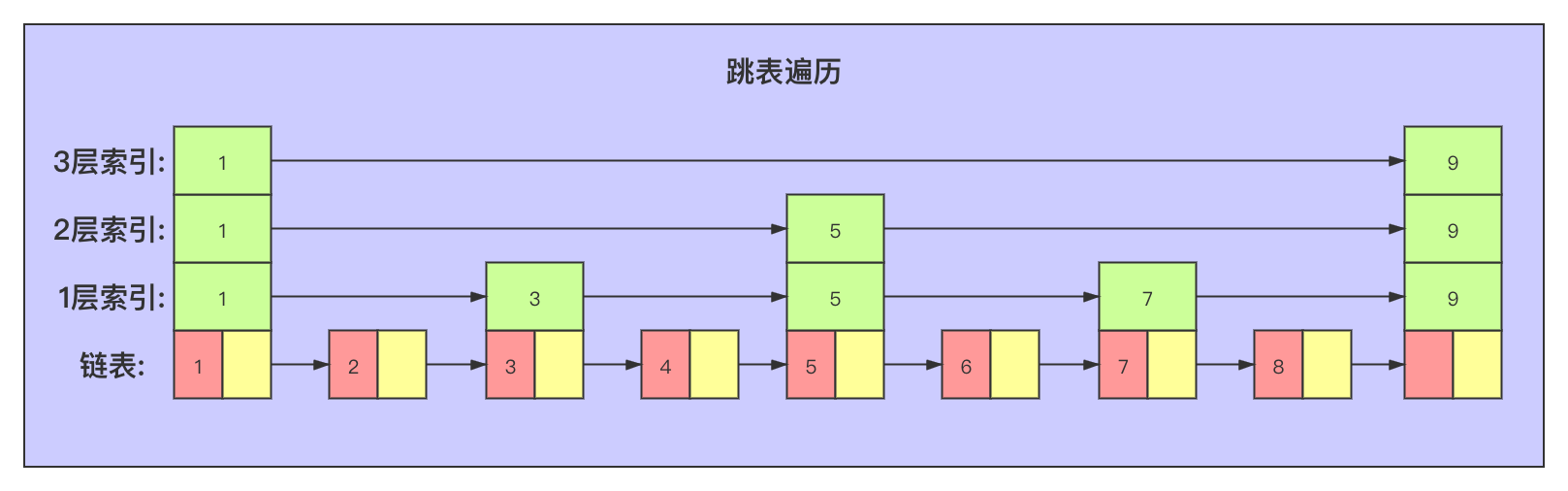
Redis跳表结构: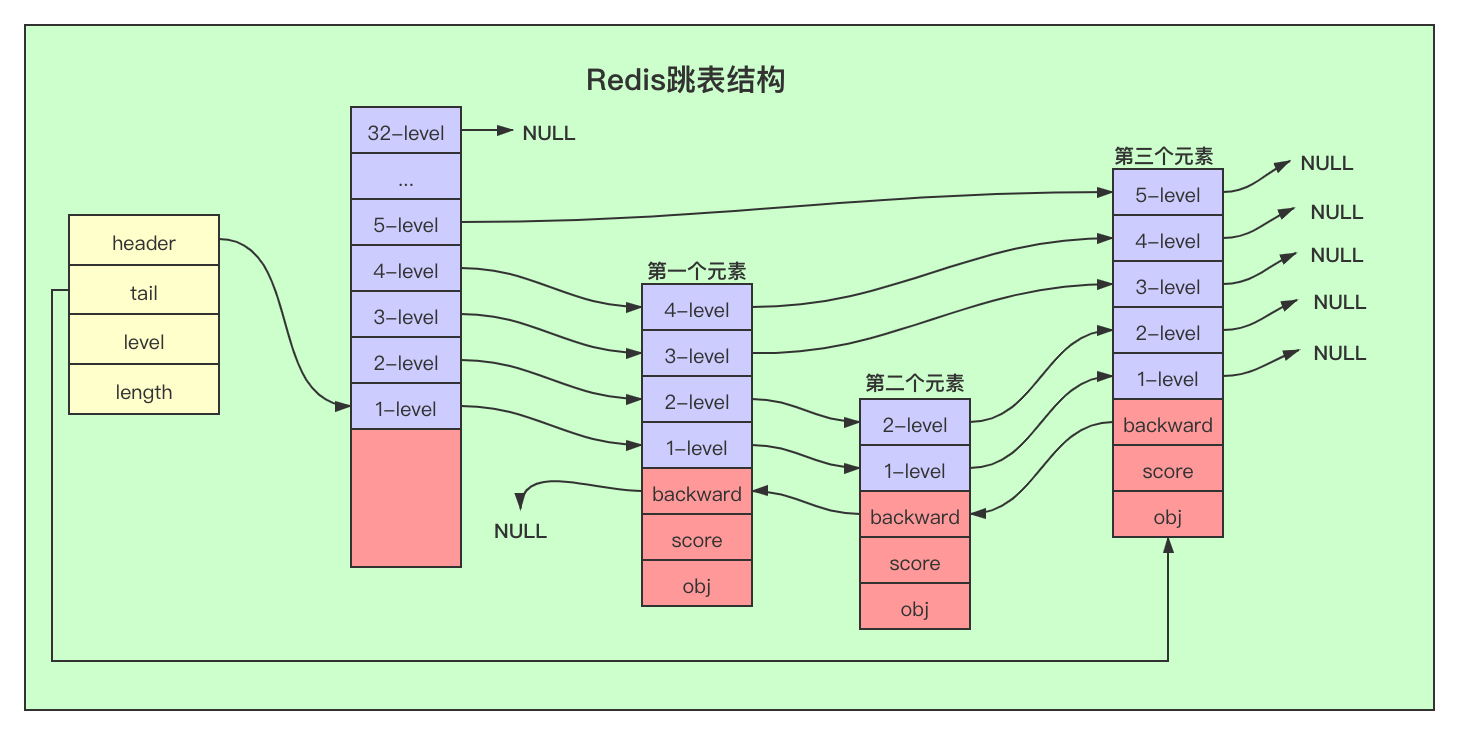
Redis跳表的元素索引存储的是链表下坐标,由于整个列表根据score排序存储,因此score的范围查询同样可以走索引。