RocketMQ(八)再均衡
简单介绍
在集群消费模式下,消费组内各Consumer均摊订阅的队列信息,也就是消费端的负载均衡机制。在消费过程中如果队列、消费组信息发生变化,则需要根据分配策略对组内所有Consumer重新分配队列,这个过程就是再均衡(rebalance)。
队列变化
1.当Broker节点因为宕机、停止等原因导致服务不可用时,触发一次rebalance,重新分配消费组队列: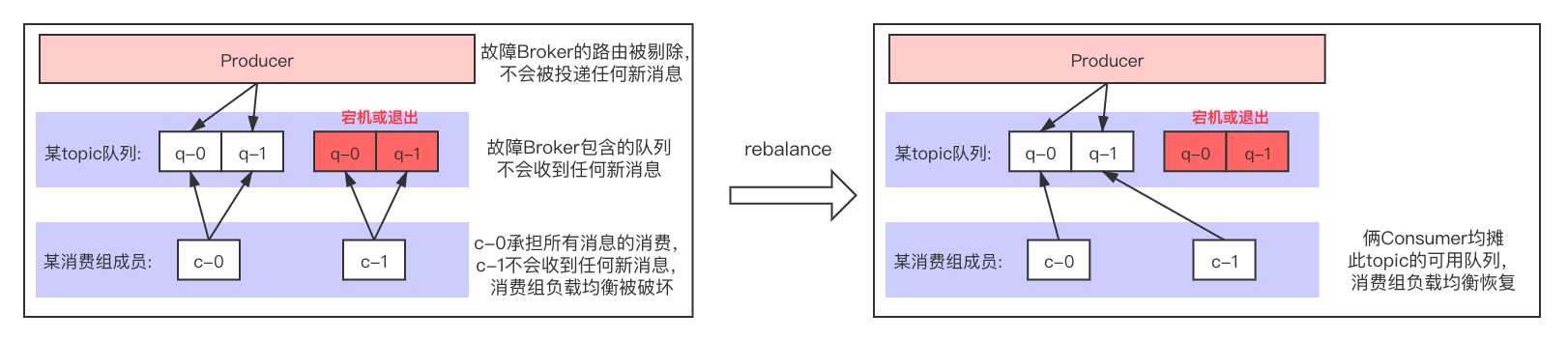
2.当故障Broker节点重新启动后,触发一次rebalance,重新分配消费组的订阅队列: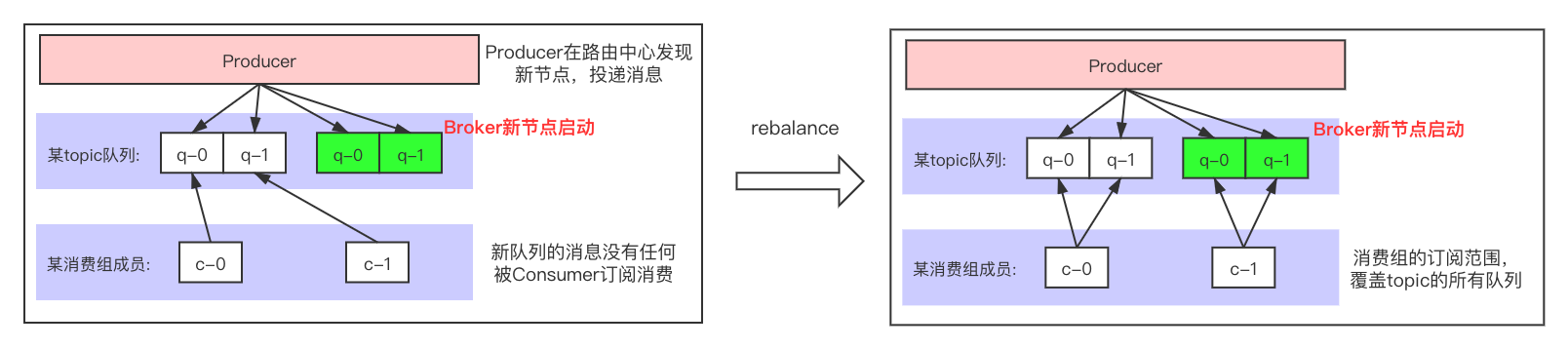
3.当Broker节点的某个topic进行队列扩容时(为了明显一点,使用环形分配策略):
4.当Broker节点的某个topic进行队列缩容时:
消费组变化
1.当消费组启动一个Consumer时,触发一次rebalance,重新分配消费组队列:
2.当消费组某个Consumer因为宕机、停止、网络异常导致无法与Broker心跳等原因停止消费时,触发一次rebalance,重新分配消费组队列:
rebalance过程
整个过程由Broker检测并通知Consumer端,Consumer端接收到通知后调用RebalanceImpl类的rebalanceByTopic()方法进行rebalance。rebalance是以topic+消费组为粒度对队列进行重分配的,例如某个组订阅了5个topic,那么会遍历这5个topic并分别调用rebalanceByTopic()方法执行rebalance。
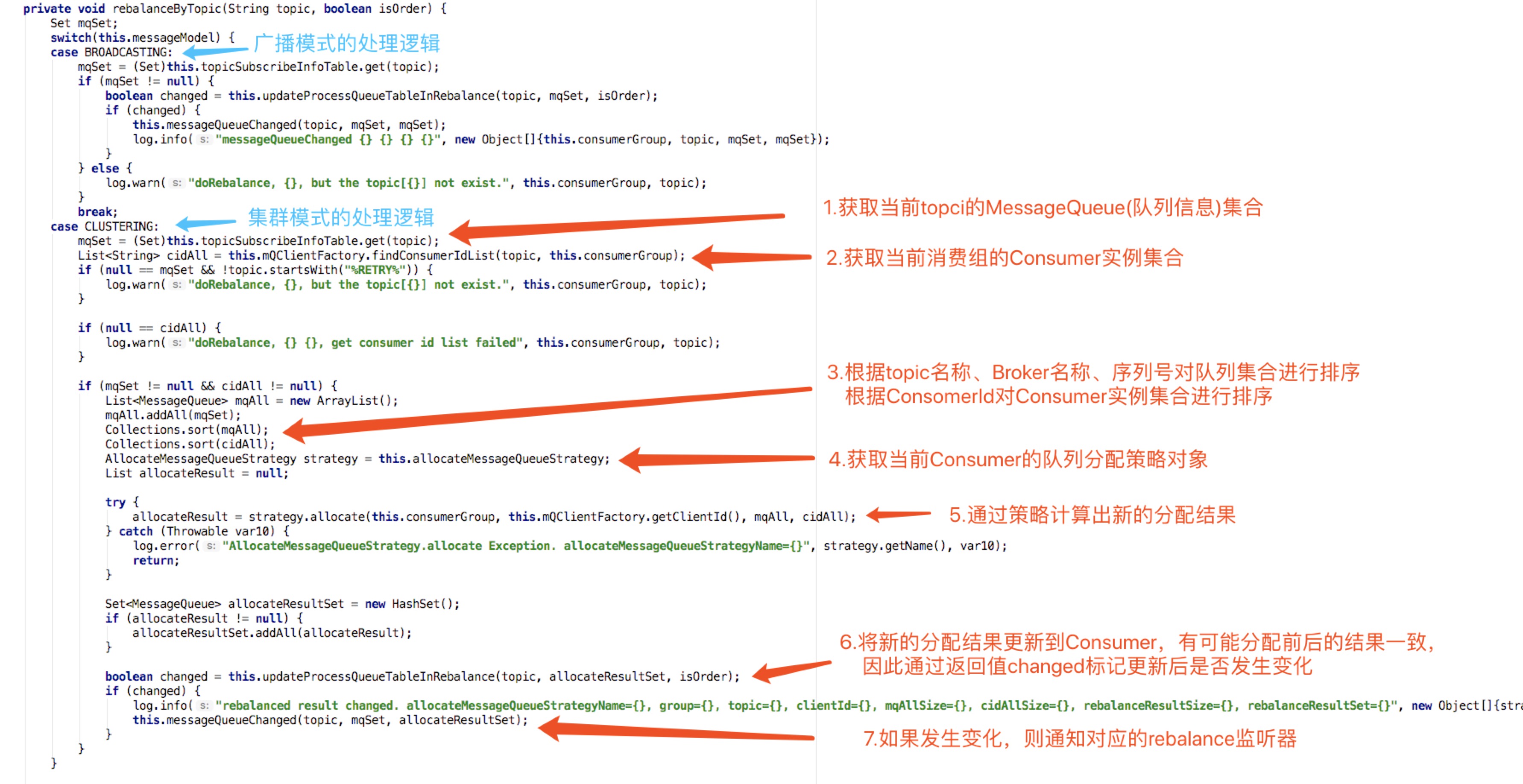
注意:由于rebalance都是通过Broker端发起通知,为了防止特殊原因导致Consumer端没有收到通知错过rebalance,Consumer端会开启RebalanceService线程,每隔10秒钟对订阅的topic进行一次rebalance。
分配策略
平均分配策略(默认)(AllocateMessageQueueAveragely)
1 | public List<MessageQueue> allocate(String consumerGroup, String currentCID, List<MessageQueue> mqAll,List<String> cidAll) { |
各种情况下Queue分配情况: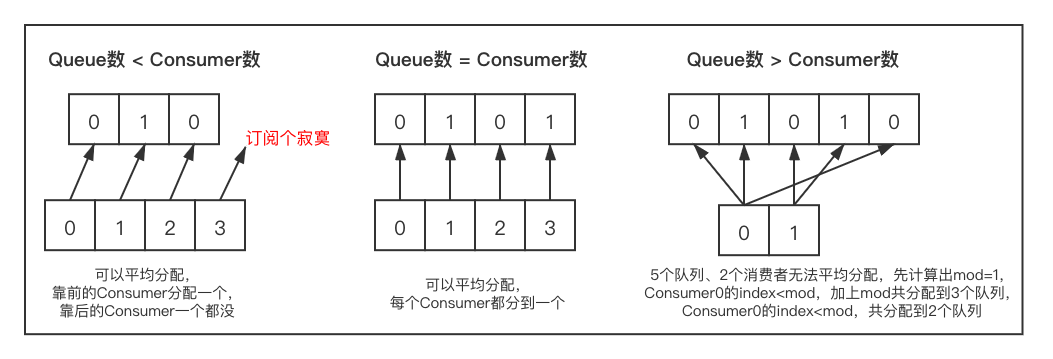
环形分配策略(AllocateMessageQueueAveragelyByCircle)
1 | public List<MessageQueue> allocate(String consumerGroup, String currentCID, List<MessageQueue> mqAll, List<String> cidAll) { |
各种情况下Queue分配情况: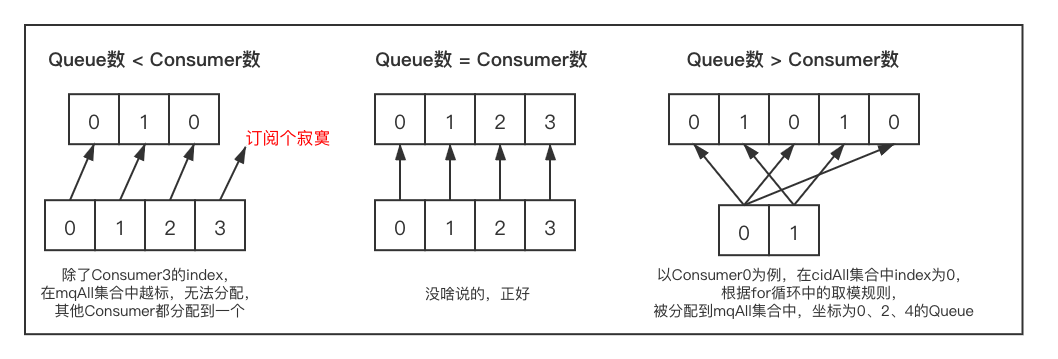
手动配置分配策略(AllocateMessageQueueByConfig)
自己发挥
机房分配策略(AllocateMessageQueueByMachineRoom)
感觉与平均分配策略的逻辑差不多,就近机房的逻辑判断没看懂
一致性哈希分配策略(AllocateMessageQueueConsistentHash)
牵涉到一致性哈希算法,以后在更新
与kafka区别
Kafka是在消费组的众多Consumer中,选举一个作为Group Leader,由这个Group Leader来计算出分配结果并同步给其他Consumer,这种机制很好的避免了脑裂问题。
RocketMQ中,Consumer端无论是主动收到通知、还是RebalanceService线程触发的rebalance,都是每个Consumer自己按照分配策略给自己重新分配队列。如果消费组内各Consumer设置的分配策略以及获取的队列信息相同,那么计算出的分配结果也是相同的,不会有任何问题,如果不相同会导致脑裂,造成多个Consumer抢夺一个队列,有的队列无人问津。