RocketMQ(七)消费端
springboot1.X集成
RocketMQ依赖
1 | <dependency> |
application.properties
1 | # 服务端口 |
启动Consumer
1 |
|
推拉模式
Consumer可以使用推模式、拉模式从Broker节点中获取消息并消费,分别对应DefaultMQPushConsumer(推模式)和DefaultMQPullConsumer(拉模式)俩个对象来实现。
拉模式(PULL)
拉模式获取消息,具体实现需要使用者在Consumer自己编写代码,先通过NameServer获取订阅topic对应的MessageQueue列表,遍历此列表对每个MessageQueue对象批量获取消息,并记录该队列下一次要取的开始offset,获取完毕后在处理下一个MessageQueue。
这种模式由Consumer端主动向Broker节点发送请求拉取消息,拉取的相关逻辑可以自由控制(比如拉取频率、单次批量拉取数量等),因此不会出现消息堆积的情况,只要专注维护每个队列的offset即可(最好在数据库维护,能与消费业务在一个事务中更好)。缺点也很明显,Consmuer端无法准确地决定何时去拉取最新的消息,循环时间间隔太短容易忙等,浪费CPU资源,时间间隔太长client的处理能力会下降,导致有些时候消息延迟。
于是阿里采用长轮询的方式来解决这个问题,Consumer发送请求到Broker拉取消息,如果Broker发现没有消息不会直接返回,而是把连接挂起(wait),直到Producer投递新的消息过来在对请求线程进行唤醒返回(notify)
。为了避免请求连接被阻塞对系统的开销,需要使用者根据自身业务场景合理的评估时间间隔,设置消费者对于长轮询的等待时间,由consumerTimeoutMillisWhenSuspend属性控制。
推模式(PUSH)
推模式获取消息,DefaultMQPushConsumer在启动时需指定MessageListenerConcurrently监听器,用于监听最新的消息,达到实时消费的效果。然而严格意义上讲,RcoketMQ并没有提供任何Broker主动推消息的功能,PUSH的本质是consumer对PULL的一层封装,让使用者感觉消息是通过Broker推送过来的。
DefaultMQPushConsumer在启动成功后,会启动一个线程并运行类似while(true)的方法疯狂的去pullRequestQueue队列里面take()元素pullRequest,可以理解为队列里面的每一个pullRequest元素都是一个需求,需求的内容就是去Broker拉取消息(PullRequest对象就是拉取消息的参数)。如果没有元素说明此时不需要拉取消息,将线程自身挂起,如果有就取出并调用pullMessage方法访问Broker进行拉取,pullMessage方法内部是对PULL的一层封装,拉取到消息后扔给线程池的消费处理函数,无论拉没拉取到消息,都会将pullRequest元素放回队列。
由此可以看出推模式的本质还是拉模式,区别在于推模式是写个死循环一直调用PULL,相当于和Broker一直保持联系。拉消息、消费消息由不同的线程取处理,这就导致一个问题,如果订阅的主题,Producer投递消息的速度远超Consumer的消费能力,会导致消费端拉消息的线程拉取了大量的消息不能及时被消费线程处理掉,造成消息堆积。
最后messageListenerConcurrently的作用貌似是监听订阅的topic发生变化后,通知用。
消费模式
RocketMQ的Consumer支持集群和广播俩种消费模式,可在初始化方法中指定,消费模式用于决定Consumer订阅Broker节点中topic-queue的分配规则。
集群模式
集群模式中,消费组名称相同的Consumer实例被视为一个Consumer集群,集群内部所有Consumer实例共同承担订阅的topic,在各个Borker节点中队列的消费工作。比如现在有个名为order的topic在Broker-a和Broker-b节点中各有4个队列,并且Group_A消费组有3个Consumer在订阅,Group_B消费组有4个Consumer在订阅: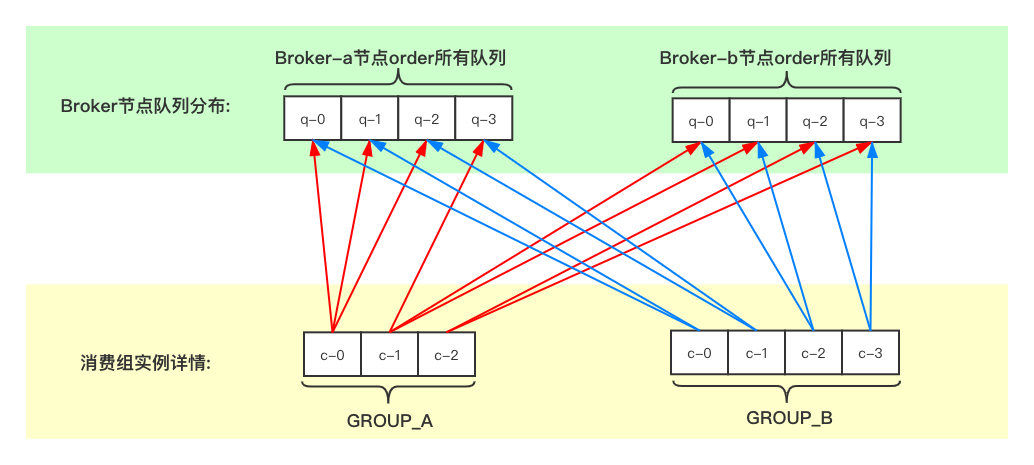
图中可以看出不同的消费组分配情况相互隔离,互不影响。同一组内的各Consumer实例按照分配策略对应一部分队列,如果总队列数正好等于Consmuer数,那么直接按一对一方式分配;如果总队列数大于Consmuer数并且是其倍数,按照一对多的方式平均分配(如上图的GROUP_B);如果总队列数大于Consmuer数但不是其倍数,仍然按照一对多的方式,会有个别Consumer被多分配一个(如上图的GROUP_A);如果总队列数小于Consmuer数,先将队列按一对一分配出去,剩下的Consumer不会被分配到任何队列,也就接收不到任何消息。
将多个Consumer划分到一个组内的作用是topic的消息进行分片,采用并行处理的方式提高消费能力。另外一个作用是实现消费失败重试机制,因为Consumer在进行消费时可能因为各种异常导致消费逻辑执行失败,并返回RECONSUME_LATER状态,遇到这种情况会将消息回发到Broker,然后Broker尝试重新发送。
最后,在使用集群模式进行消费时,所有消费组名称以及订阅topic的所有队列的消费进度(逻辑偏移量),全部存储在对应的Broker节点上(上篇文章讲到的config文件夹的consumerOffset.json文件中),Consumer不进行任何进度的存储。
广播模式
广播模式中,任何一条消息都会发送到消费组内所有Consumer进行消费。也就是说消费组内有几个Consumer实例,消息就会被处理几遍。在实现方式上较集群模式简单一些,不用考虑队列分配情况: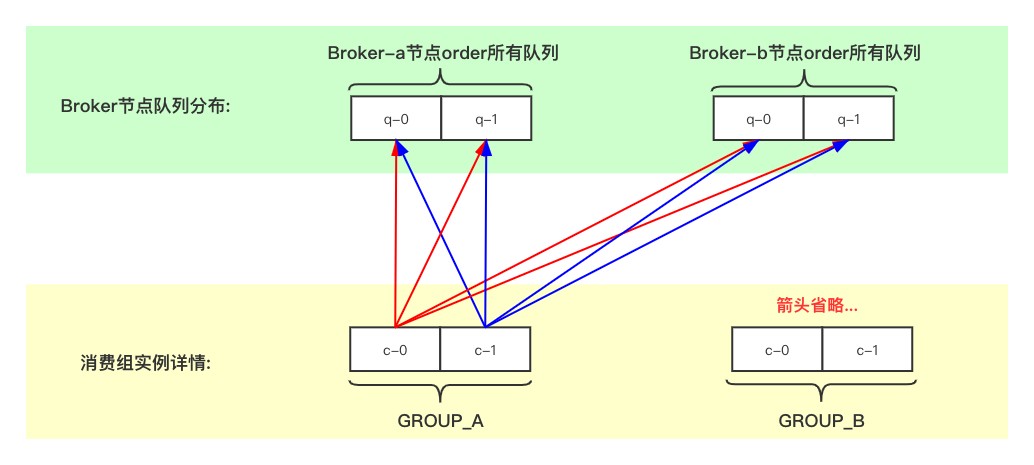
与集群模式不同,广播模式下的Consumer在出现消费失败时(返回RECONSUME_LATER状态)不会进行失败重投,所以使用广播模式要额外关注消费失败情况,做好应对措施,防止消费失败引起的消息丢失。另外一个不同点是,消费组内每个Consumer消费进度由自身维护,源码中是LocalFileOffsetStore类负责记录存储。
顺序消费
顺序消费首先要保证Producer将顺序的消息发送到同一个Queue中,然后单个Queue只会被单个Consumer消费,这一点是由RocketMQ的分配机制保证。以上的Demo代码是使用MessageListenerConcurrently并发监听,说明白点就是Consumer即使顺序的拉取到消息,也会采用多线程并行消费消息,仍然无法保证消费的顺序。
对此RocketMQ中提供了MessageListenerOrderly来实现真正的顺序消费,实现此接口并重写ConsumeOrderlyStatus方法,其他与并行消费没区别:
1 |
|
MessageListenerOrderly使用风险:
- 并行消费变为串行消费,降低了Consumer的消费能力
- 如果某条消息在消费失败时,不会将失败告诉Broker执行重试,并且队列消费暂停
消息过滤
Tag、SQL92和类过滤器(新版去除)
订阅关系一致
同一个消费组内的所有Consumer还需遵循订阅关系一致性原则,才能保证消息的正常消费。这个原则要求消费组内的所有Consumer订阅的topic和对应tags必须保持一致,一旦订阅关系不一致就会导致消费混乱,甚至消息丢失。
消费组的订阅信息在Broker的存储结构由ConsumerManager类的consumerTable进行维护:
1 | private final ConcurrentMap<String/* Group */, ConsumerGroupInfo> consumerTable = |
ConsumerGroupInfo类存储了消费组的具体结构,类内部的subscriptionTable存储的topic的订阅详情:
1 | private final ConcurrentMap<String/* Topic */, SubscriptionData> subscriptionTable = |
SubscriptionData类存储了订阅的所有规则信息:
1 | public class SubscriptionData implements Comparable<SubscriptionData> { |
由上面结构可以看出,消费组的订阅信息是以groupName为单位进行保存。当Consumer启动后,会将自己的订阅信息(List
要想搞清楚这个问题,还需要清楚Consumer是如何去Broker拉取消息的,上面的推拉模式也简单说过,推模式是将PullRequest作为参数拉取消息,那就要知道PullRequest对象内部都有什么属性:
1 | public class PullRequest { |
到这里问题就差不多搞清楚了,Consumer在拉取消息时,根据consumerGroup和topic获取到SubscriptionData对象,也就是消费组的订阅信息。然后根据对应的queueId以及nextOffset拉取消息,并按照订阅消息配置的tags以及filter等对消息进行筛选拉取,消费完毕后提交offset。
由于同一时刻NameServer保存的订阅信息只有一份,当同一消费组内的Consumer订阅关系不一致时,与NameServer保存的信息不符合的那部分Consumer会拉取到不属于自己的消息。比如tags不一致,会拉取到别的tags,如果topic不一致,直接报the consumer’s subscription not exist错误。
消费重试
Consumer端的消费失败分为俩种,一种是EXCEPTION,另一种是TIMEOUT,当Broker感知到Consumer端消费失败后,会根据不同的失败类型采取不同的措施。Consumer的消费重试机制,仅仅在集群模式中有效,广播模式不会进行消息重试。
EXCEPTION
exception是指Consumer正常接收到消息后,在进行消费处理过程中发生异常,比如要将消息的内容插入数据库,正巧此时数据库宕机,又或者消息对应数据库查询出来的数据是脏数据,导致逻辑处理走不通等。这些都会引起消费逻辑的异常,通常我们会将消息的处理代码块使用try catch包起来(上面的例子),如果正常执行就返回CONSUME_SUCCESS,抓取到异常就返回RECONSUME_LATER。
无论如何,Broker都会收到Consumer端的消费结果情况,如果成功就更新offset,如果失败重新尝试推送,重试次数默认是16次,考虑到异常恢复起来需要一些时间,所以每次重试都有一定的时间间隔,间隔依次为1S,5S,10S,30S,1M,2M····2H。RocketMQ会为每个消费组创建一个格式为%RETRY%+consumerGroup的重试队列,对于消费失败的消息根据间隔时间将其放入延迟topic(SCHEDULE_TOPIC_XXXX),到达延迟时间点后发送到对应的重试队列,然后再次投递到Consumer。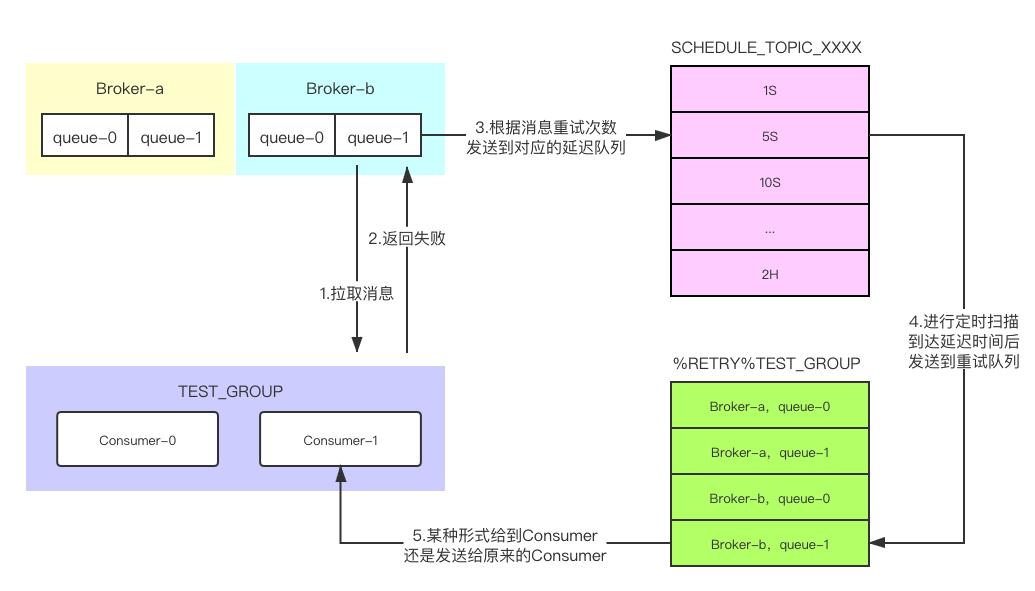
实际开发中也许并不需要这么多重试次数,比如只需要3次重试次数,超过这个次数就记录到数据库或缓存,然后开启定时器等扫描在处理,或者人为干涉修复。这种方式首先要在Consumer设置重试次数,然后在消费前调用MessageExt类的getReconsumeTimes()方法查看重试次数,如果超过设置次数则将消息保存到数据库或缓存,然后直接返回CONSUME_SUCCESS。
TIMEOUT
TIMEOUT是指因为种种原因导致Consumer端没有及时给Broker反馈消息的处理状态,导致Broker认为消息并没有被消费掉,然后会一直发送消息。超时时间可以调用Consumer的setConsumeTimeout()方法设置,默认为15(单位分钟)。
死信队列
当消息遇到EXCEPTION,并达到重试次数限制后仍然未成功,消息会投递到DLQ死信队列(%DLQ%RetryConsumer),可以在控制台进行查看:
死信队列特点:
- 死信队列是以%DLQ%+消费组名称进行命名,换句话说每个消费组都有自己的死信队列
- 消费组在未产生死信消息的情况下,不会创建死信队列
- 消费组的死信队列包含组内所有的topic所属的死信消息,换句话说组内订阅的topic共享一个死信队列
消息回溯
回溯消费是指Consumer已经消费成功的消息,由于业务上需求需要重新消费,消息回溯就是对这种场景的支持。Consumer是基于队列的offset进行拉取消息,因此消息回溯的只需要重新指定topic和queue的offset即可,另外RocketMQ还支持按照时间回溯消费,时间维度精确到毫秒,可以向前回溯,也可以向后回溯。
Consumer启动重置offset
在Consumer端配置中,可以通过setConsumeFromWhere(ConsumeFromWhere)方法设置启动后消费的起点offset,其中传入参数ConsumeFromWhere是个枚举类:
1 | public enum ConsumeFromWhere { |
控制台重置offset
进入控制台点击Topic导航栏,筛选出topic行信息后,点击REST CONSUMER OFFSET按钮,选择要重置的消费组以及回溯时间: