1.概述
DirectByteBuffer是直接缓冲区,也就是说缓冲的数据并不在JVM堆内,而是在内核内存中。在执行IO操作时,也就省去了从堆内存到JNI内存、从JNI内存到内核内存两次拷贝,效率大大提高。但堆外内存的回收不受GC的影响,需要在Java层面自己去管理。
DirectByteBuffer的底层通过mmap()系统函数实现,可以通过文件映射或匿名映射的方式申请堆外内存,重写ByteBuffer类的抽象方法时,也都是直接对内存地址进行操作。
2.映射方式
2.1 文件映射
对磁盘文件的映射,是将磁盘文件的整体或部分区域,映射到进程的虚拟地址空间,这块虚拟地址存在与之对应的一块磁盘地址。在Java中,文件映射通过FileChannel类实现:
1
2
3
4
5
6
7
8
9
10
11
| public static void main(String[] args) throws Exception{
RandomAccessFile raf = new RandomAccessFile("/文件路径", "rw");
FileChannel fileChannel = raf.getChannel();
MappedByteBuffer mappedByteBuffer = fileChannel.map(FileChannel.MapMode.READ_WRITE, 0, (int) fc.size());
}
|
FileChannel类的map()方法,虽然映射大小在方法参数中是long类型,但内部的校验逻辑却不允许值超出Integer.MAX_VALUE,也就是单次最多映射2个G大小(2^32个字节),如果文件超出2G需要分成多段映射。Java层面并没有对映射的总大小进行限制,使用不当会引起本机内存溢出。
2.2 匿名映射
内存映射可以不依赖磁盘文件,本质上是按照申请大小在物理内存(内存条)上选择一块区域,映射到进程的虚拟地址空间,不关联其他任何设备源,在Linux系统中通过malloc()函数实现。在Java中,ByteBuffer提供了静态方法实现:
1
2
3
| public static void main(String[] args) throws Exception{
ByteBuffer byteBuffer = ByteBuffer.allocateDirect(1024);
}
|
匿名映射的总大小受JVM参数:-XX:MaxDirectMemorySize限制,默认和JVM堆大小保持一致,如果申请时超出限制则JVM堆内存溢出。这只是JVM层面的限制,当请求到达操作系统层面,还会存在本机的RAM、SWAP、CPU寻址空间等限制。
3.MappedByteBuffer
MappedByteBuffer是DirectByteBuffer的抽象父类,但内部所有功能都是针对文件映射设计的,如果是通过匿名映射方式创建,就没有对应的磁盘文件,那么调用MappedByteBuffer方法会报错,具体的细节在下面源码中会讲解。
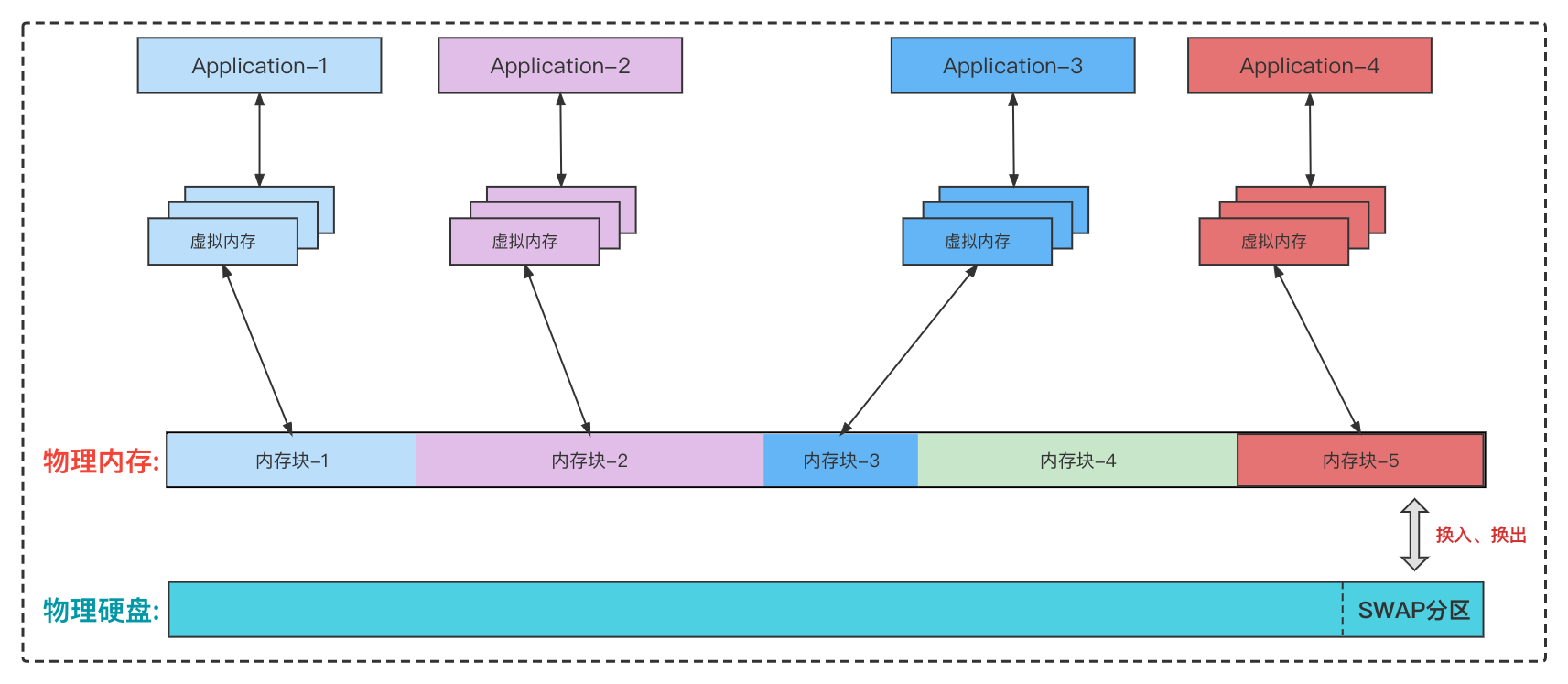
3.1 SWAP机制
SWAP机制是操作系统对运行内存使用率的优化,当操作系统的物理内存不够使用时,会将一部分暂时不会被使用的内存释放出来,也就是写在硬盘上,以供当前运行的程序使用,这个现象称为换出。那些被释放的空间可能来自一些很长时间没有什么操作的程序,等到那些程序要运行时,再从硬盘的Swap分区中,将原先保存的数据加载回物理内存,这个现象称为换入。
并不是所有的内存数据都会被交换到Swap分区中,有相当一部分数据被直接交换到文件系统。例如通过文件映射生成的内存,当内存使用紧张时,临时交换到硬盘的Swap分区没有意义,可以直接刷回对应的文件所在地址,下次恢复直接根据文件地址读取数据到内存即可;通过匿名映射生成的内存,不会像前者那样有个地方可以持久化,因此必须要交换到Swap分区。
3.2 缺页机制
现在的操作系统基本都采用分页的形式管理内存,这个分页机制与文件系统的PageCache很相似,但完全是两个不同的东西。对于文件映射出来的内存想要持久化到硬盘,是将数据委托给文件系统,而多数文件系统会先将数据写入PageCache,然后在合适的时候刷回硬盘。内存中的数据无论回到文件系统、还是SWAP分区,都是以页为单位进行IO。
在创建DirectByteBuffer后,并不会直接分配物理内存,当第一次访问数据地址时,操作系统会产生一个缺页异常,触发中断后将数据从硬盘加载到物理内存中,后续还有可能又被换入Swap分区。MappedByteBuffer提供了相关方法,检查当前映射的数据是否已加载到物理内存,或者手动加载到物理内存中。
3.3 成员变量和构造器
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| public abstract class MappedByteBuffer extends ByteBuffer{
private static byte unused;
private final FileDescriptor fd;
MappedByteBuffer(int mark, int pos, int lim, int cap, FileDescriptor fd){
super(mark, pos, lim, cap);
this.fd = fd;
}
MappedByteBuffer(int mark, int pos, int lim, int cap) {
super(mark, pos, lim, cap);
this.fd = null;
}
}
|
MappedByteBuffer共有两个构造器,第一个构造器供文件映射创建时使用,需要指定磁盘文件的描述符对象;第二个构造器供匿名映射创建时使用,不需要指定磁盘文件的描述符。
成员变量unused好像没啥用,不过这个fd很有意思,FileChannel类的map()方法中,并没有将真正的描述符对象传入构造器,而是创建了一个新的描述符对象,里面的描述符值永远是-1。其实读完源码就会明白,fd的作用只是通过是否为null来判断创建的方式。
3.4 native方法
1
2
3
4
5
6
7
8
|
private native boolean isLoaded0(long address, long length, int pageCount);
private native void load0(long address, long length);
private native void force0(FileDescriptor fd, long address, long length);
|
3.5 private方法
①映射校验,如果fd为null,代表当前类是通过匿名映射创建的,如果fd不为null,代表当前类是通过文件映射创建的。MappedByteBuffer类所有对外提供的功能都是针对文件映射的,因此所有public修饰方法的第一行代码,都会调用此方法验证当前类的创建方式:
1
2
3
4
| private void checkMapped() {
if (fd == null)
throw new UnsupportedOperationException();
}
|
②映射内存的偏移量,FileChannel类的map()方法可以通过position参数,指定映射的起始地址,也就是说address不一定刚好在某个页的开始位置,此方法就是用于计算address的所在页,与页开始位置的字节距离:
1
2
3
4
5
| private long mappingOffset() {
int ps = Bits.pageSize();
long offset = address % ps;
return (offset >= 0) ? offset : (ps + offset);
}
|
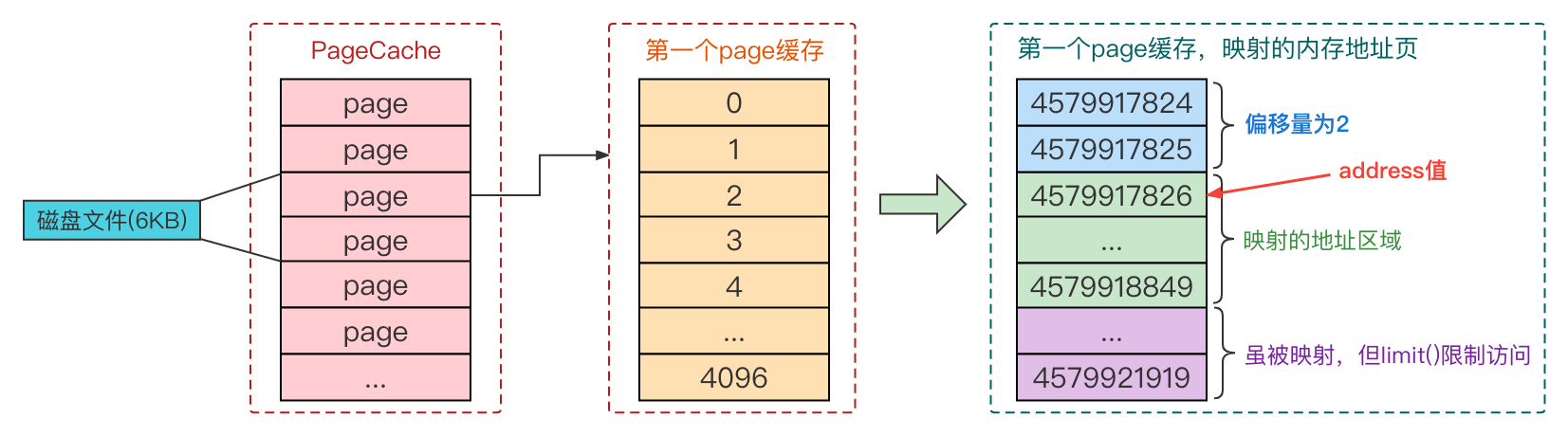
假设选择一个6KB大小的磁盘文件,通过map()方法进行映射,position设置为2、size设置为1024,偏移量如图:
③映射内存的访问地址,在指定position值映射文件时,address不一定正好落在某个页的起始位置,但内存映射的最小单位为页,必然会被加载到虚拟内存以及物理内存中。因此想要得到实际映射地址值,需要根据映射偏移量,往前推一段距离:
1
2
3
| private long mappingAddress(long mappingOffset) {
return address - mappingOffset;
}
|
假设选择一个6KB大小的磁盘文件,通过map()方法进行映射,position设置为2、size设置为1024,实际映射地址如图:

④映射内存的地址长度,在偏移量大于零的情况下,实际映射内存地址肯定要比address小一些,那么地址的长度也是一样的道理。address对应的长度就是容量,需要在加上偏移量值:
1
2
3
| private long mappingLength(long mappingOffset) {
return (long)capacity() + mappingOffset;
}
|
假设选择一个6KB大小的磁盘文件,通过map()方法进行映射,position设置为2、size设置为1024,实际映射长度如图:

3.6 public方法
判断当前对象映射的文件地址,是否已经加载到物理地址(内存条)中:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
| public final boolean isLoaded() {
checkMapped();
if ((address == 0) || (capacity() == 0))
return true;
long offset = mappingOffset();
long length = mappingLength(offset);
return isLoaded0(mappingAddress(offset), length, Bits.pageCount(length));
}
|
将当前对象映射的文件地址,加载到物理地址(内存条)中:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
| public final MappedByteBuffer load() {
checkMapped();
if ((address == 0) || (capacity() == 0))
return this;
long offset = mappingOffset();
long length = mappingLength(offset);
load0(mappingAddress(offset), length);
Unsafe unsafe = Unsafe.getUnsafe();
int ps = Bits.pageSize();
int count = Bits.pageCount(length);
long a = mappingAddress(offset);
byte x = 0;
for (int i=0; i<count; i++) {
x ^= unsafe.getByte(a);
a += ps;
}
if (unused != 0)
unused = x;
return this;
}
|
将映射内存区域的内容,持久化到磁盘上,底层通过msync()系统函数:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| public final MappedByteBuffer force() {
checkMapped();
if ((address != 0) && (capacity() != 0)) {
long offset = mappingOffset();
force0(fd, mappingAddress(offset), mappingLength(offset));
}
return this;
}
|
4.DirectByteBuffer
4.1 成员变量
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
| class DirectByteBuffer extends MappedByteBuffer implements DirectBuffer{
protected static final Unsafe unsafe = Bits.unsafe();
private static final long arrayBaseOffset = (long)unsafe.arrayBaseOffset(byte[].class);
protected static final boolean unaligned = Bits.unaligned();
private final Object att;
private final Cleaner cleaner;
}
|
4.2 构造器
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
| DirectByteBuffer(int cap) {
super(-1, 0, cap, cap);
boolean pa = VM.isDirectMemoryPageAligned();
int ps = Bits.pageSize();
long size = Math.max(1L, (long)cap + (pa ? ps : 0));
Bits.reserveMemory(size, cap);
long base = 0;
try {
base = unsafe.allocateMemory(size);
} catch (OutOfMemoryError x) {
Bits.unreserveMemory(size, cap);
throw x;
}
unsafe.setMemory(base, size, (byte) 0);
if (pa && (base % ps != 0)) {
address = base + ps - (base & (ps - 1));
} else {
address = base;
}
cleaner = Cleaner.create(this, new Deallocator(base, size, cap));
att = null;
}
|
4.2 读写方法
重写ByteBuffer的三个读取方法:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
|
public byte get() {
return ((unsafe.getByte(ix(nextGetIndex()))));
}
public byte get(int i) {
return ((unsafe.getByte(ix(checkIndex(i)))));
}
public ByteBuffer get(byte[] dst, int offset, int length) {
if (((long)length << 0) > Bits.JNI_COPY_TO_ARRAY_THRESHOLD) {
checkBounds(offset, length, dst.length);
int pos = position();
int lim = limit();
assert (pos <= lim);
int rem = (pos <= lim ? lim - pos : 0);
if (length > rem)
throw new BufferUnderflowException();
Bits.copyToArray(ix(pos), dst, arrayBaseOffset,
(long)offset << 0,
(long)length << 0);
position(pos + length);
} else {
super.get(dst, offset, length);
}
return this;
}
|
重写ByteBuffer的四个写入方法:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
|
public ByteBuffer put(byte x) {
unsafe.putByte(ix(nextPutIndex()), ((x)));
return this;
}
public ByteBuffer put(int i, byte x) {
unsafe.putByte(ix(checkIndex(i)), ((x)));
return this;
}
public ByteBuffer put(ByteBuffer src) {
if (src instanceof DirectByteBuffer) {
if (src == this)
throw new IllegalArgumentException();
DirectByteBuffer sb = (DirectByteBuffer)src;
int spos = sb.position();
int slim = sb.limit();
assert (spos <= slim);
int srem = (spos <= slim ? slim - spos : 0);
int pos = position();
int lim = limit();
assert (pos <= lim);
int rem = (pos <= lim ? lim - pos : 0);
if (srem > rem)
throw new BufferOverflowException();
unsafe.copyMemory(sb.ix(spos), ix(pos), (long)srem << 0);
sb.position(spos + srem);
position(pos + srem);
} else if (src.hb != null) {
int spos = src.position();
int slim = src.limit();
assert (spos <= slim);
int srem = (spos <= slim ? slim - spos : 0);
put(src.hb, src.offset + spos, srem);
src.position(spos + srem);
} else {
super.put(src);
}
return this;
}
public ByteBuffer put(byte[] src, int offset, int length) {
if (((long)length << 0) > Bits.JNI_COPY_FROM_ARRAY_THRESHOLD) {
checkBounds(offset, length, src.length);
int pos = position();
int lim = limit();
assert (pos <= lim);
int rem = (pos <= lim ? lim - pos : 0);
if (length > rem)
throw new BufferOverflowException();
Bits.copyFromArray(src, arrayBaseOffset,
(long)offset << 0,
ix(pos),
(long)length << 0);
position(pos + length);
} else {
super.put(src, offset, length);
}
return this;
}
|
基本上和HeapByteBuffer的重写逻辑差不多,只不过HeapByteBuffer的position对应数组的坐标,而DirectByteBuffer的position对应映射地址的偏移量。
4.3 复制方法
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
public ByteBuffer slice() {
int pos = this.position();
int lim = this.limit();
assert (pos <= lim);
int rem = (pos <= lim ? lim - pos : 0);
int off = (pos << 0);
assert (off >= 0);
return new DirectByteBuffer(this, -1, 0, rem, rem, off);
}
public ByteBuffer duplicate() {
return new DirectByteBuffer(this, this.markValue(), this.position(), this.limit(), this.capacity(), 0);
}
public ByteBuffer asReadOnlyBuffer() {
return new DirectByteBufferR(this, this.markValue(), this.position(), this.limit(), this.capacity(), 0);
}
|
4.4 其他方法
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
| public ByteBuffer compact() {
int pos = position();
int lim = limit();
assert (pos <= lim);
int rem = (pos <= lim ? lim - pos : 0);
unsafe.copyMemory(ix(pos), ix(0), (long)rem << 0);
position(rem);
limit(capacity());
discardMark();
return this;
}
public boolean isDirect() {
return true;
}
public boolean isReadOnly() {
return false;
}
|
5.堆外内存释放
JVM可以回自动收堆内的DirectByteBuffer对象,但对应的堆外内存的释放必须通过Unsafe类的freeMemory()方法,而DirectByteBuffer类并没有封装相关方法供开发者使用完毕后调用,而是在对象创建的时候就生成一个钩子函数,当DirectByteBuffer被GC回收时触发,释放对应的堆外内存。
5.1 Deallocator
DirectByteBuffer对象的构造器中,会将自身以及一个Deallocator对象封装成一个Cleaner实例,用于后续的堆外内存回收:
1
2
3
4
5
|
cleaner = Cleaner.create(this, new Deallocator(base, size, cap));
cleaner = Cleaner.create(this, unmapper);
|
Deallocator是DirectByteBuffer的私有内部类,在创建时需要指定堆外内存的信息,并将堆外内存释放的逻辑代码封装在run()方法内部,供Cleaner调用:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
| private static class Deallocator implements Runnable {
private static Unsafe unsafe = Unsafe.getUnsafe();
private long address;
private long size;
private int capacity;
private Deallocator(long address, long size, int capacity) {
assert (address != 0);
this.address = address;
this.size = size;
this.capacity = capacity;
}
public void run() {
if (address == 0) {
return;
}
unsafe.freeMemory(address);
address = 0;
Bits.unreserveMemory(size, capacity);
}
}
|
5.2 Cleaner
Cleaner类的源码就不写了,它本质上是个虚引用对象,并且顶层继承是Reference抽象类,Reference抽象类内部有个静态的单向链表,当某个DirectByteBuffer实例除了Reference实现类之外,没有其他强引用时,这些Reference实现类会被JVM放入Reference抽象类的静态单向链表。
Reference抽象类的内部还有一个静态代码块,初始化一个名叫ReferenceHandler的线程,这个线程是个优先级很高的守护线程,启动后会不停的循环上述的静态单向链表,如果不为空就根据情况作出对应的逻辑处理:
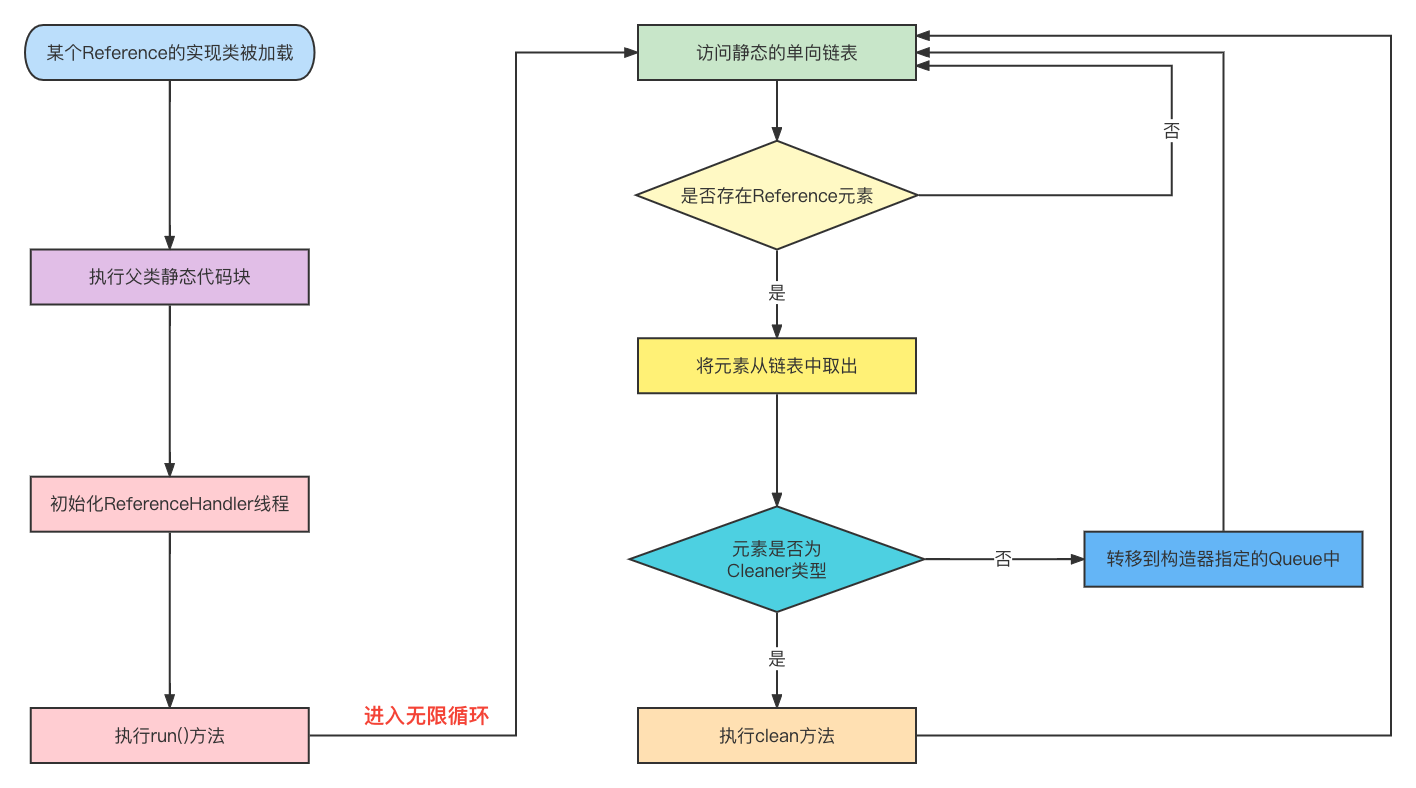
从流程图中可以看出,JDK对Cleaner类型的虚引用做了特殊处理,强转并调用clean()方法,到这里就触发DirectByteBuffer实例创建时注册的钩子函数,使堆内对象与对应的堆外内存一起被释放。关于虚引用的原理,这里讲的比较简单,如果想要掌握具体的实现,还得去看Reference源码。
5.3 att属性
堆外内存释放还有个细节,例如创建一个DirectByteBuffer实例记作A,调用A的slice()或duplicate()或asReadOnlyBuffer()方法生成实例B,此时A和B内部的address是同一块地址,当A除了虚引用Cleaner外没有其他引用时,A的Cleaner触发钩子函数,如果此时实例B仍在使用,会导致内部的address失效,造成程序错误。
DirectByteBuffer的解决办法,是为slice()、duplicate()、asReadOnlyBuffer()方法专门提供一个构造器,将实例A初始化为实例B的att属性,如果B还在使用时,就会强引用A,那么就不会触发A的Cleaner的钩子函数。