1.概述
BufferedInputStream、BufferedOutputStream是带有缓冲区的字节处理流,默认的缓冲区字节数组大小为8192(8KB),通过装饰器模式对InputStream、OutputStream的功能进行增强,每次读写都是基于内部缓冲区操作,当缓冲区存储的字节超过一定数量时,才会进行真正的磁盘IO,这样能够有效减少磁盘的访问次数,从而提高读写的性能。
虽然缓冲处理流能装饰一切InputStream、OutputStream的子类,但是对序列化流、数据处理流等的装饰毫无意义,因为读写规则比较特殊,对数组字节流的装饰更是画蛇添足,因为这种流本身就基于内存。因此缓冲处理流的装饰对象基本都是文件、网络等,这种场景才能减少与操作系统或IO设备的交互次数。
2.简单使用
2.1 数据写入
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
| public static void main(String[] args) throws Exception{
FileInputStream fis = new FileInputStream("you path");
BufferedInputStream bufis = new BufferedInputStream(fis);
byte[] bytes = new byte[1024];
int len = 0;
while((len = bufis.read(bytes))!=-1) {
System.out.println(new String(bytes, 0, len));
}
bufis.close();
}
|
2.2 数据读取
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
| public static void main(String[] args) throws Exception{
FileOutputStream fos = new FileOutputStream("you path");
BufferedOutputStream bufos = new BufferedOutputStream(fos);
bufos.write(1);
bufos.flush();
bufis.close();
}
|
3.1 成员变量
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
|
private static int DEFAULT_BUFFER_SIZE = 8192;
private static int MAX_BUFFER_SIZE = Integer.MAX_VALUE - 8;
protected volatile byte buf[];
private static final
AtomicReferenceFieldUpdater<BufferedInputStream, byte[]> bufUpdater =
AtomicReferenceFieldUpdater.newUpdater
(BufferedInputStream.class, byte[].class, "buf");
protected int count;
protected int pos;
protected int markpos = -1;
protected int marklimit;
|
3.2 mark & reset
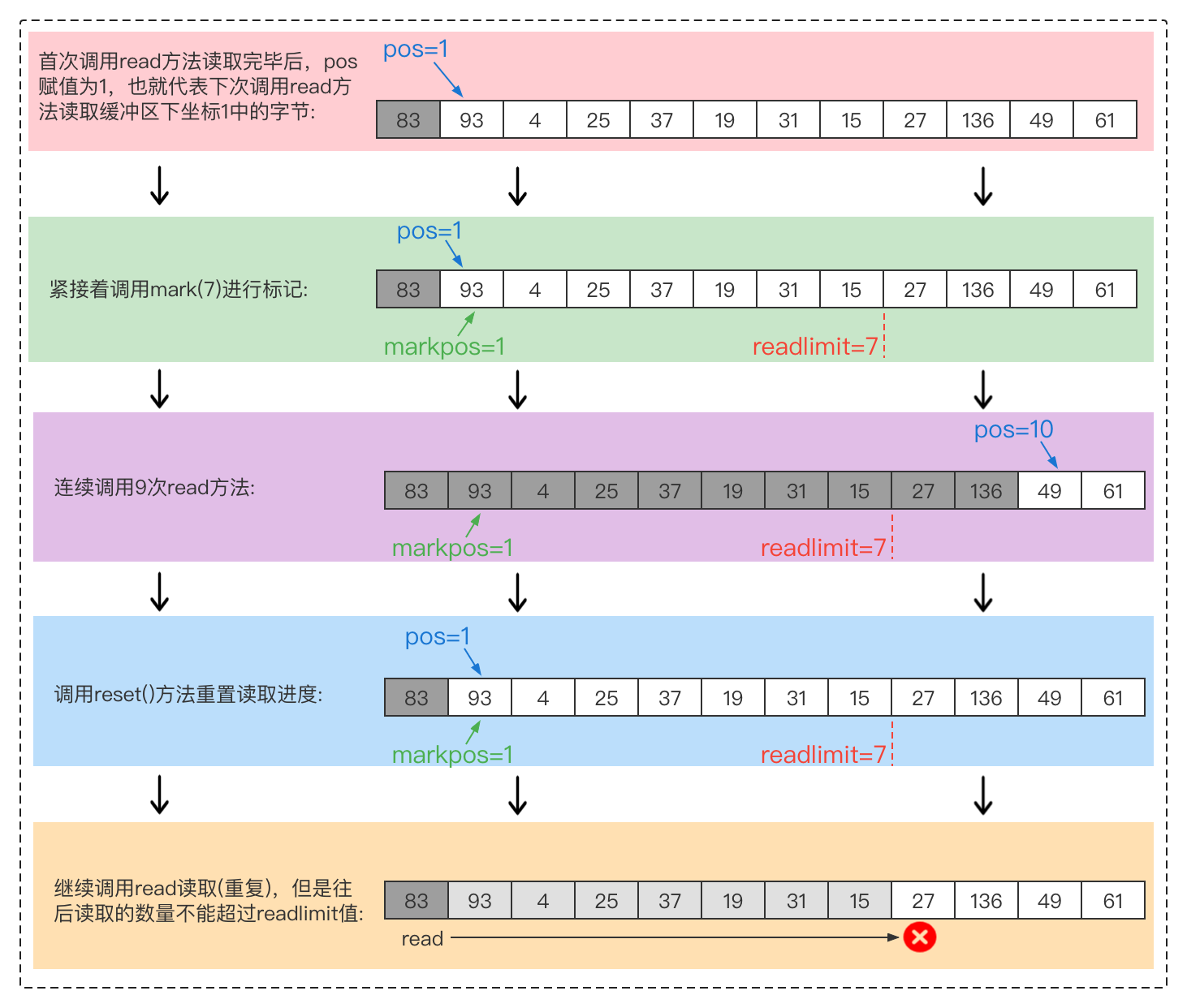
BufferedInputStream支持流的重复读取,而这个功能就是通过mark和reset方法进行实现。以单字节方式读取一段缓冲流为例:
方法源码:
1
2
3
4
5
6
7
8
9
10
11
12
13
|
public synchronized void mark(int readlimit) {
marklimit = readlimit;
markpos = pos;
}
public synchronized void reset() throws IOException {
getBufIfOpen();
if (markpos < 0)
throw new IOException("Resetting to invalid mark");
pos = markpos;
}
|
mark与reset方法是InputStream提供的接口,在这里讲解主要是因为使用标记后,会让BufferedInputStream的缓冲区管理变得复杂,因此只有搞清楚这块的逻辑,才能研究接下来的方法。
3.3 fill
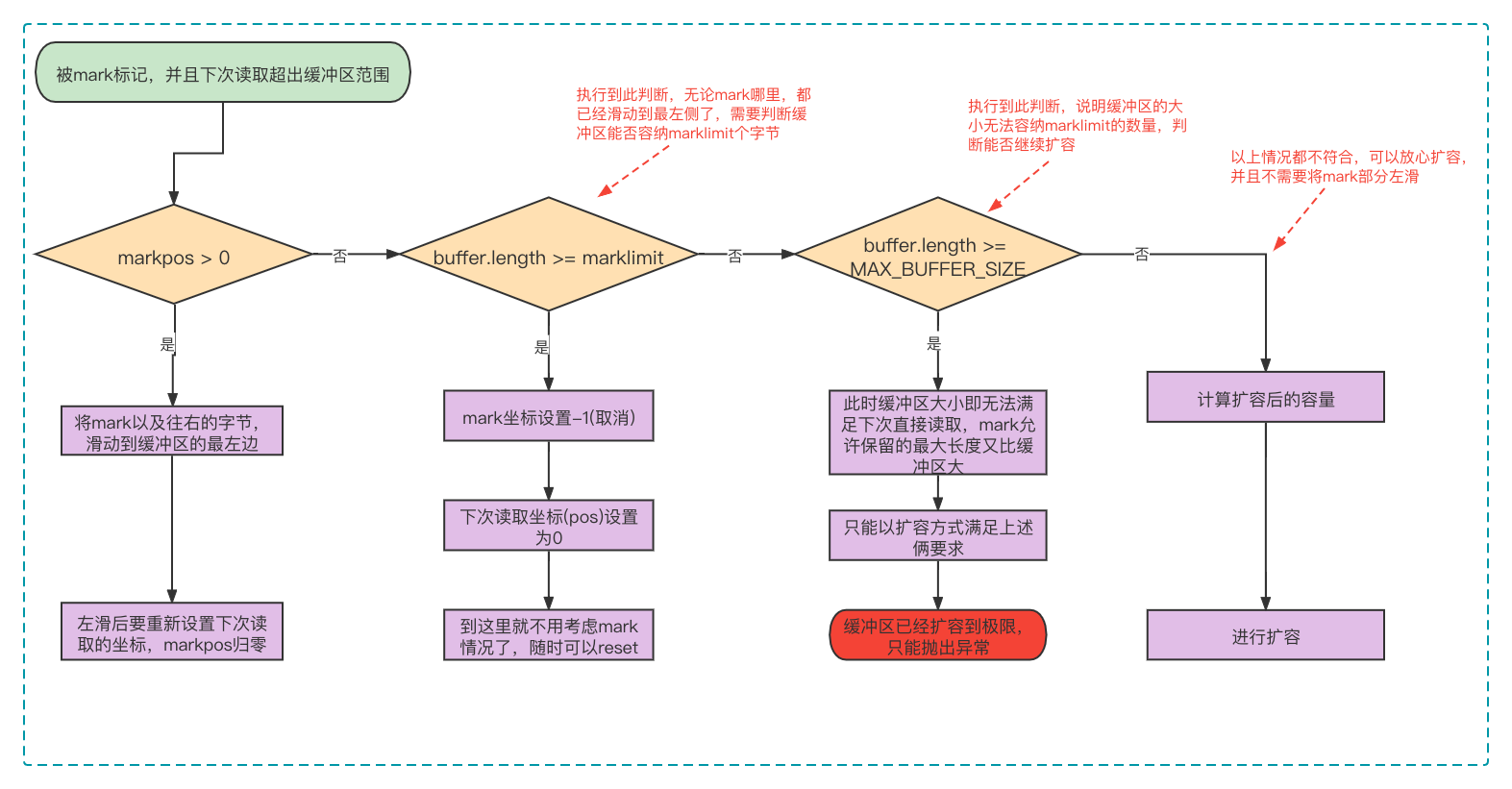
在读取数据时,如果缓冲区的数据已经全部读完,则需要将缓冲区的字节重新填装,fill方法就是通过数据滑动的方式实现缓冲区填装,方法的具体源码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
| private void fill() throws IOException {
byte[] buffer = getBufIfOpen();
if (markpos < 0)
pos = 0;
else if (pos >= buffer.length)
if (markpos > 0) {
int sz = pos - markpos;
System.arraycopy(buffer, markpos, buffer, 0, sz);
pos = sz;
markpos = 0;
} else if (buffer.length >= marklimit) {
markpos = -1;
pos = 0;
} else if (buffer.length >= MAX_BUFFER_SIZE) {
throw new OutOfMemoryError("Required array size too large");
} else {
int nsz = (pos <= MAX_BUFFER_SIZE - pos) ?
pos * 2 : MAX_BUFFER_SIZE;
if (nsz > marklimit)
nsz = marklimit;
byte nbuf[] = new byte[nsz];
System.arraycopy(buffer, 0, nbuf, 0, pos);
if (!bufUpdater.compareAndSet(this, buffer, nbuf)) {
throw new IOException("Stream closed");
}
buffer = nbuf;
}
count = pos;
int n = getInIfOpen().read(buffer, pos, buffer.length - pos);
if (n > 0)
count = n + pos;
}
|
代码有点晦涩难懂,首先缓冲区在没字节可读的情况下才会调用fill(),如果此BufferedInputStream对象没有调用过mark,那么处理起来是最简单的,把下次读取的坐标设置为缓冲区的首坐标(pos=0),从装饰器的输入流中读取缓冲区大小的字节,将缓冲区以覆盖形式填满新字节,下次从头读取。
被mark调用过就比较麻烦,可以看看else if (pos >= buffer.length)执行流程图:
3.3 read(单字节)
1
2
3
4
5
6
7
8
9
10
11
12
13
| public synchronized int read() throws IOException {
if (pos >= count) {
fill();
if (pos >= count)
return -1;
}
return getBufIfOpen()[pos++] & 0xff;
}
|
3.4 read(多字节)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
| public synchronized int read(byte b[], int off, int len)
throws IOException
{
getBufIfOpen();
if ((off | len | (off + len) | (b.length - (off + len))) < 0) {
throw new IndexOutOfBoundsException();
} else if (len == 0) {
return 0;
}
int n = 0;
for (;;) {
int nread = read1(b, off + n, len - n);
if (nread <= 0)
return (n == 0) ? nread : n;
n += nread;
if (n >= len)
return n;
InputStream input = in;
if (input != null && input.available() <= 0)
return n;
}
}
|
私有方法一次读取多个字节(尽量读,有可能填装完还读不满len):
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
| private int read1(byte[] b, int off, int len) throws IOException {
int avail = count - pos;
if (avail <= 0) {
if (len >= getBufIfOpen().length && markpos < 0) {
return getInIfOpen().read(b, off, len);
}
fill();
avail = count - pos;
if (avail <= 0) return -1;
}
int cnt = (avail < len) ? avail : len;
System.arraycopy(getBufIfOpen(), pos, b, off, cnt);
pos += cnt;
return cnt;
}
|
4.BufferedOutputStream
缓冲处理输出流相对输入流来说,不用考虑mark后字节的保存情况,也不用考虑缓冲区的扩容情况,唯一要考虑的就是写完后需要手动flush,确保缓冲区数据都刷新到装饰的输入流,因为写入时只有缓冲区满了才会自动刷新。
4.1 成员变量
1
2
3
4
5
6
|
protected byte buf[];
protected int count;
|
4.2 write(单字节)
1
2
3
4
5
6
7
8
9
| public synchronized void write(int b) throws IOException {
if (count >= buf.length) {
flushBuffer();
}
buf[count++] = (byte)b;
}
|
调用私有方法,将写入缓冲区的字节数组同步到装饰的输出流:
1
2
3
4
5
6
7
8
9
| private void flushBuffer() throws IOException {
if (count > 0) {
out.write(buf, 0, count);
count = 0;
}
}
|
4.3 write(多字节)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
| public synchronized void write(byte b[], int off, int len) throws IOException {
if (len >= buf.length) {
flushBuffer();
out.write(b, off, len);
return;
}
if (len > buf.length - count) {
flushBuffer();
}
System.arraycopy(b, off, buf, count, len);
count += len;
}
|