1.概述
DataInputStream即数据输入流,DataOutputStream即数据输出流,允许应用程序以与机器无关方式从底层输入流中读取Java基本数据类型。这俩个类分别继承FilterInput/OutputStream,内部采用装饰器模式对Input/OutputStream的功能进行增强。
与机器无关是因为Java基础数据类型结构简单,转化为字节并存储的逻辑也相对简单,其他机器或语言可以轻松复原。另外数据处理流通过UTF-8编码封装了对String类型的读写,UTF-8编码在各机器或者语言都是通用的,因此字符串的处理也不受平台的影响。
2.简单使用
2.1 数据写入
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
| public static void main(String[] args) throws Exception{
FileOutputStream fos = new FileOutputStream("you path");
DataOutputStream dos = new DataOutputStream(fos);
dos.writeBoolean(true);
dos.writeChar('哈');
dos.writeByte(7);
dos.writeShort(12);
dos.writeInt(25);
dos.writeLong(39);
dos.writeFloat(4.1f);
dos.writeDouble(9.8);
dos.writeUTF("IO流");
}
|
查看生成的文件内容:

对应结构:
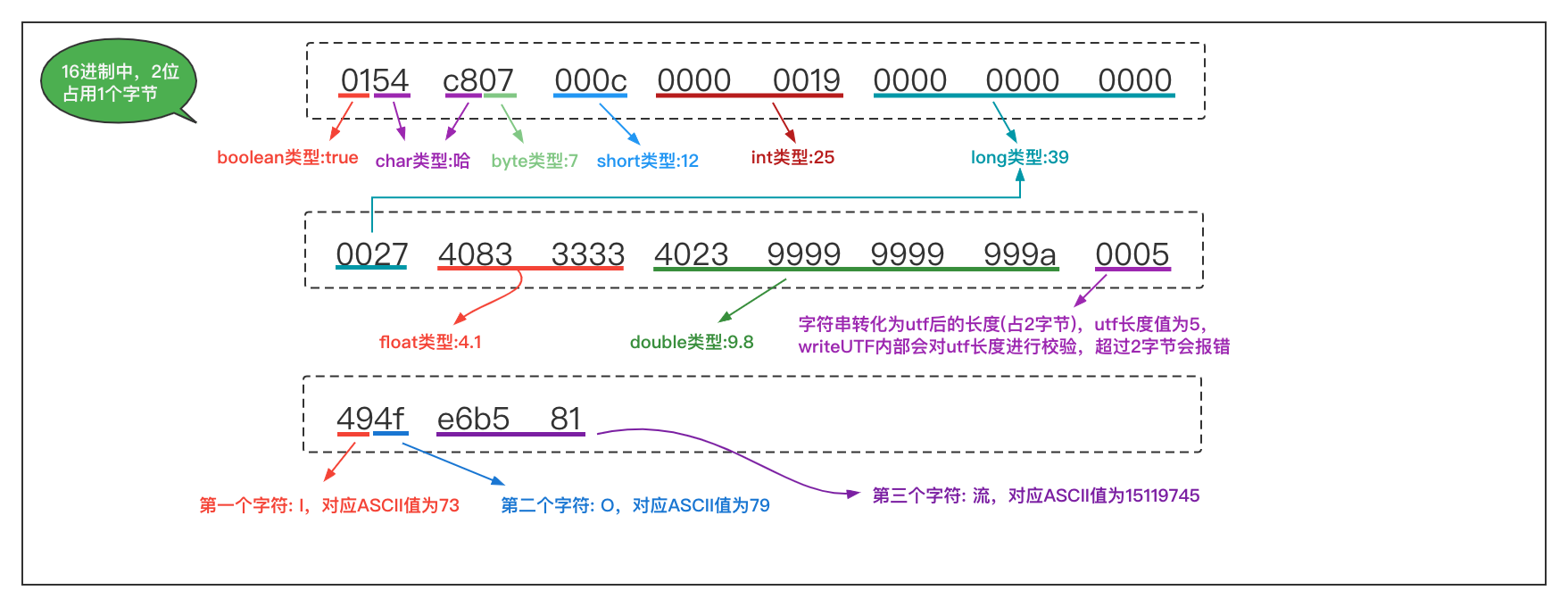
首次写入不同的基本数据类型,生成文件的默认编码集也不同,例如写入boolean、char字母或数字、正整数等类型生成的文件是binary编码,这种编码通过文本编辑器打开文件后,会以上图所示的16进制正常展示。
写入char汉字生成的文件是iso-8859-1编码(不支持中文表达),因此打开的文件内容是乱码。最后Double、Int负数、UTF等类型是unkown-8bit编码,文本编辑器软件仍然无法正常识别并展示,还是会出现奇奇怪怪的字符。
Mac笔记本可以通过file -I 文件路径查看文件的编码集,如果文件的编码集无法被文本编辑器正常显示(我使用的是Sublime Text,也可能是文本编辑器的原因),通过hexdump -v 文件路径命令查看原始16进制内容,得到上图的查看效果。
2.2 数据读取
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
| public static void main(String[] args) throws Exception{
FileInputStream fis = new FileInputStream("you path");
DataInputStream dis = new DataInputStream(fis);
System.out.println(dos.readBoolean());
System.out.println(dos.readChar());
System.out.println(dos.readByte());
System.out.println(dos.readShort());
System.out.println(dos.readInt());
System.out.println(dos.readLong());
System.out.println(dos.readFloat());
System.out.println(dos.readDouble());
System.out.println(dis.readUTF());
}
|
注: DataOutputStream是将基本数据类型转化为字节挨个存储,因此DataInputStream在读取数据时,要遵循写入时的顺序,否则会读取失败。
3.DataOutputStream
先从写入开始研究,提供的写入方法整体比较多,但万变不离其宗,都是转化为字节然后调用内部装饰的InputStream类进行字节写入,就简单研究几个有代表性的方法。
3.1 writeBoolean
1
2
3
4
5
6
| public final void writeBoolean(boolean v) throws IOException {
out.write(v ? 1 : 0);
incCount(1);
}
|
1
2
3
4
5
6
7
8
9
10
| private void incCount(int value) {
int temp = written + value;
if (temp < 0) {
temp = Integer.MAX_VALUE;
}
written = temp;
}
|
3.2 writeInt
1
2
3
4
5
6
7
8
9
10
11
12
13
|
public final void writeInt(int v) throws IOException {
out.write((v >>> 24) & 0xFF);
out.write((v >>> 16) & 0xFF);
out.write((v >>> 8) & 0xFF);
out.write((v >>> 0) & 0xFF);
incCount(4);
}
|
例如现在写入一个值为330067683的int数据类型:
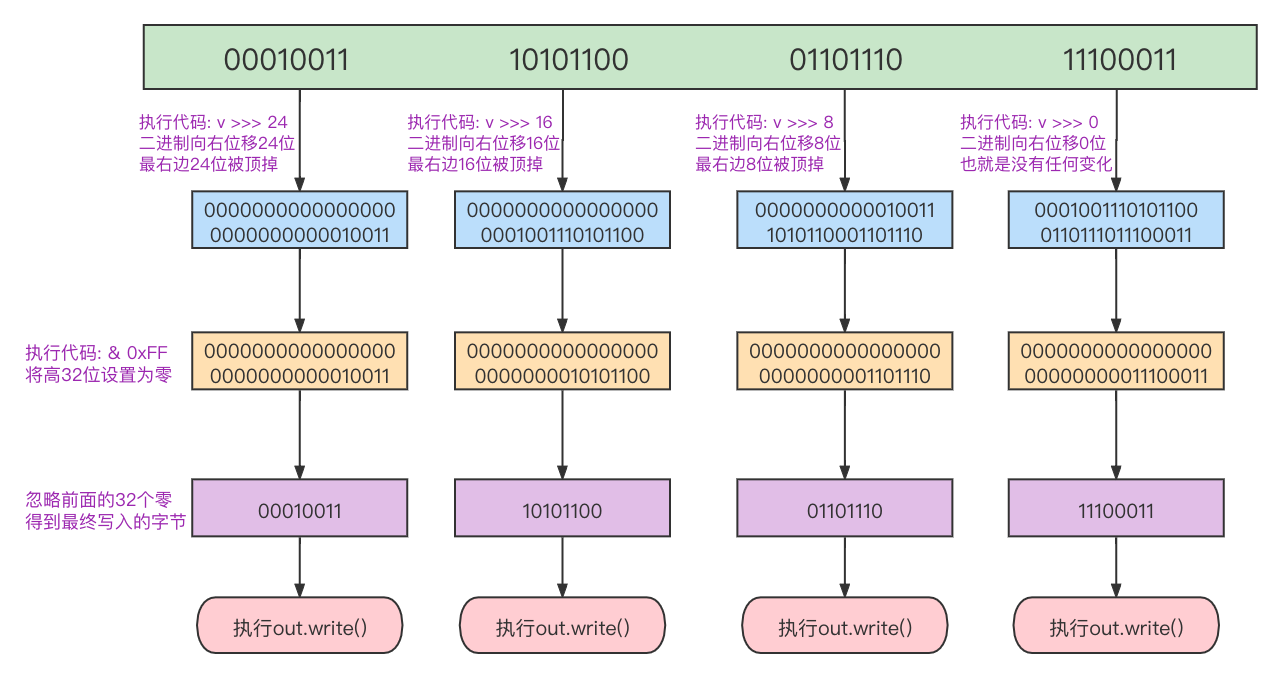
类似的还有char、byte、sort、long这四个基本类型的写入,都是直接将对应二进制以字节为单位进行拆分,然后调用内部装饰OutputStream类的write单字节逐次写入。long类型稍微特殊一点,是将拆分的8个字节放进数组中批量写入,只和操作系统交互一次。
3.3 writeFloat
1
2
3
4
| public final void writeFloat(float v) throws IOException {
writeInt(Float.floatToIntBits(v));
}
|
1
2
3
4
5
6
7
8
9
10
11
12
| public static int floatToIntBits(float value) {
int result = floatToRawIntBits(value);
if ( ((result & FloatConsts.EXP_BIT_MASK) ==
FloatConsts.EXP_BIT_MASK) &&
(result & FloatConsts.SIGNIF_BIT_MASK) != 0)
result = 0x7fc00000;
return result;
}
|
3.4 writeUTF
writeUTF方法并没有真正写入,而是将自身作为参数交给静态方法处理:
1
2
3
| public final void writeUTF(String str) throws IOException {
writeUTF(str, this);
}
|
真正处理写入逻辑的静态方法:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
|
static int writeUTF(String str, DataOutput out) throws IOException {
int strlen = str.length();
int utflen = 0;
int c, count = 0;
for (int i = 0; i < strlen; i++) {
c = str.charAt(i);
if ((c >= 0x0001) && (c <= 0x007F)) {
utflen++;
} else if (c > 0x07FF) {
utflen += 3;
} else {
utflen += 2;
}
}
if (utflen > 65535)
throw new UTFDataFormatException(
"encoded string too long: " + utflen + " bytes");
byte[] bytearr = null;
if (out instanceof DataOutputStream) {
DataOutputStream dos = (DataOutputStream)out;
if(dos.bytearr == null || (dos.bytearr.length < (utflen+2)))
dos.bytearr = new byte[(utflen*2) + 2];
bytearr = dos.bytearr;
} else {
bytearr = new byte[utflen+2];
}
bytearr[count++] = (byte) ((utflen >>> 8) & 0xFF);
bytearr[count++] = (byte) ((utflen >>> 0) & 0xFF);
int i=0;
for (i=0; i<strlen; i++) {
c = str.charAt(i);
if (!((c >= 0x0001) && (c <= 0x007F))) break;
bytearr[count++] = (byte) c;
}
for (;i < strlen; i++){
c = str.charAt(i);
if ((c >= 0x0001) && (c <= 0x007F)) {
bytearr[count++] = (byte) c;
} else if (c > 0x07FF) {
bytearr[count++] = (byte) (0xE0 | ((c >> 12) & 0x0F));
bytearr[count++] = (byte) (0x80 | ((c >> 6) & 0x3F));
bytearr[count++] = (byte) (0x80 | ((c >> 0) & 0x3F));
} else {
bytearr[count++] = (byte) (0xC0 | ((c >> 6) & 0x1F));
bytearr[count++] = (byte) (0x80 | ((c >> 0) & 0x3F));
}
}
out.write(bytearr, 0, utflen+2);
return utflen + 2;
}
|
字符串的存储,本质上就是内部char数组的存储,由于char类型占2字节,可能是ASCII表符号,可能是其他特殊符号,也可能是汉字。对于特殊符号、汉字需要拆成多个字节存储,但每个字节只存储最多6位,空余的位做特殊标记,方便DataInputStream读取时能够识别二进制的类型。
4.1 readBoolean
1
2
3
4
5
6
7
8
9
| public final boolean readBoolean() throws IOException {
int ch = in.read();
if (ch < 0)
throw new EOFException();
return (ch != 0);
}
|
4.2 readInt
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| public final int readInt() throws IOException {
int ch1 = in.read();
int ch2 = in.read();
int ch3 = in.read();
int ch4 = in.read();
if ((ch1 | ch2 | ch3 | ch4) < 0)
throw new EOFException();
return ((ch1 << 24) + (ch2 << 16) + (ch3 << 8) + (ch4 << 0));
}
|
4.3 readFloat
1
2
3
4
| public final float readFloat() throws IOException {
return Float.intBitsToFloat(readInt());
}
|
4.4 readUTF
writeUTF方法并没有真正读取,而是将自身作为参数交给静态方法处理:
1
2
3
| public final String readUTF() throws IOException {
return readUTF(this);
}
|
真正处理读取逻辑的静态方法:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
| public final static String readUTF(DataInput in) throws IOException {
int utflen = in.readUnsignedShort();
byte[] bytearr = null;
char[] chararr = null;
if (in instanceof DataInputStream) {
DataInputStream dis = (DataInputStream)in;
if (dis.bytearr.length < utflen){
dis.bytearr = new byte[utflen*2];
dis.chararr = new char[utflen*2];
}
chararr = dis.chararr;
bytearr = dis.bytearr;
} else {
bytearr = new byte[utflen];
chararr = new char[utflen];
}
int c, char2, char3;
int count = 0;
int chararr_count=0;
in.readFully(bytearr, 0, utflen);
while (count < utflen) {
c = (int) bytearr[count] & 0xff;
if (c > 127) break;
count++;
chararr[chararr_count++]=(char)c;
}
while (count < utflen) {
c = (int) bytearr[count] & 0xff;
switch (c >> 4) {
case 0: case 1: case 2: case 3: case 4: case 5: case 6: case 7:
count++;
chararr[chararr_count++]=(char)c;
break;
case 12: case 13:
count += 2;
if (count > utflen)
throw new UTFDataFormatException(
"malformed input: partial character at end");
char2 = (int) bytearr[count-1];
if ((char2 & 0xC0) != 0x80)
throw new UTFDataFormatException(
"malformed input around byte " + count);
chararr[chararr_count++]=(char)(((c & 0x1F) << 6) |
(char2 & 0x3F));
break;
case 14:
count += 3;
if (count > utflen)
throw new UTFDataFormatException(
"malformed input: partial character at end");
char2 = (int) bytearr[count-2];
char3 = (int) bytearr[count-1];
if (((char2 & 0xC0) != 0x80) || ((char3 & 0xC0) != 0x80))
throw new UTFDataFormatException(
"malformed input around byte " + (count-1));
chararr[chararr_count++]=(char)(((c & 0x0F) << 12) |
((char2 & 0x3F) << 6) |
((char3 & 0x3F) << 0));
break;
default:
throw new UTFDataFormatException(
"malformed input around byte " + count);
}
}
return new String(chararr, 0, chararr_count);
}
|