IO流(六) 序列化流
1.概述
ObjectInputStream即对象输入流,ObjectOutputStream即对象输出流,俩者的主要功能是实现java对象和二进制字节数组的相互转化,也就是常说的序列化与反序列化,前提是java对象必须实现Serializable接口。
2.序列化
2.1 什么时候需要序列化?
当你想要持久化某个对象的时候,可以先将对象序列化为字节数组,然后使用文件流存储到磁盘中,在必要的时候在反序列化在内存中还原对象。这个一般在早期单体项目的时候会用到,比如登录会话Session存储在内存中,项目上线重启后Session消失,总不能每次都让用户重新登录吧,因此会采用序列化将所有登录信息对象持久化。现在稍大的项目都会涉及redis等缓存中间件,所以不需要考虑上述的问题。另外一重要使用场景就是RPC框架的数据传输,很多RPC框架的远程调用基于Socket长连接实现,Socket的请求接收是基于Byte数组实现,因此各服务间的远程调用携带DTO时,需要将DTO实体类进行序列化后发送、反序列化后接受。以Dubbo为例: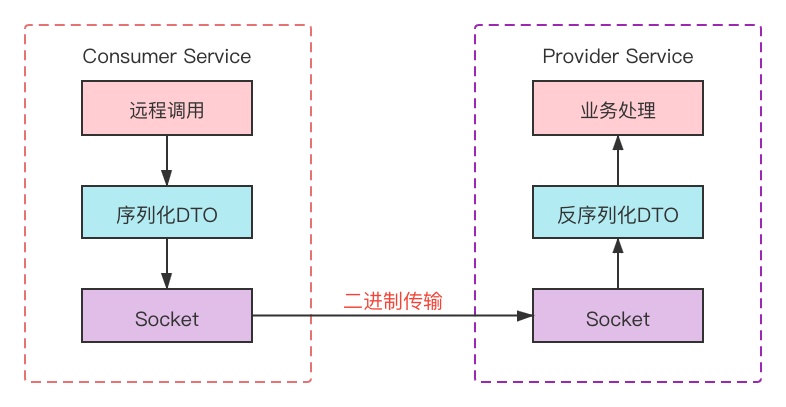
2.2 如何实现序列化?
创建一个需要序列化的实体类,然后实现Serializable接口:
1 |
|
将Book实体类序列化并存储到本地文件,然后在内存中读取恢复:
1 | public static void main(String[] args) throws Exception{ |
序列化是一个笼统的概念,具体的实现有很多种,以RPC远程调用为场景,这种设计就是约定一个规则(或者说算法),使两个jvm进程共享一个对象结构,A服务按照这个规则序列化,B服务按照约定好的规则反序列化,最终还原对象。Java提供的序列化方式是为了避免重复造轮子,毕竟使用序列化的场景很多,但这种方式也存在缺点,例如不能跨平台,因为ObjectOutputStream的序列化规则,只有它自己和ObjectInputStream知道,因此反序列化只能依靠ObjectInputStream。
采用二进制流的形式序列化的还有很多,就是各自采用不同的算法实现。除此之外还有XML序列化,以及当前最流行的JSON序列化,这些序列化方式相对于二进制流来说更轻量级、更灵活、序列化后占用空间更少,因为序列化时无需存储对象结构信息,只需要在序列化时提供结构,当然缺点是内容易读容易被截取,敏感参数需要加密。
2.2 Serializable接口
当你点开这个接口的源码时,发现里面啥也没有,注释倒是一大堆。这其实就是一个标记,告诉jvm哪些类支持被原生方法序列化,看到这里我很是疑惑,jvm运行时每个对象都有被序列化的可能,并且也不会因为实现了Serializable接口就消耗额外的资源(有也是极少),为什么不直接设计成所有类都支持序列化,这样还能减少开发者的工作量。
网上很多说序列化安全问题,也提出了一些案列,我觉得其他如json序列化也会存在这些问题。另外一个原因就是考虑到特殊类比如Thread、Socket、System等,类的创建依赖本地操作系统分配的资源,这些类的实例远程传递到另一个服务器后,即使反序列化也没有任何意义,所以在使用层面直接禁止掉。
所以类的序列化可能没有意义或者带来一些麻烦,jvm就将哪些类可以序列化的决定权交给开发者,如果开发者将某个类实现了Serializable接口,就代表你是知道风险的情况下对此类使用序列化,需要自己考虑可能出现的后果。
2.4 序列化注意项
如果类实现了Serializable接口,子类不需要实现接口也可以序列化,子类进行反序列化时只会还原自身的属性,父类属性忽略、静态和常量忽略(serialVersionUID除外),如果子类自己的普通属性也想忽略,在属性前添加transient修饰符即可。
序列化与反序列化操作可能由不同的jvm进程完成,例如RPC的消费者执行序列化、提供者执行反序列化,这俩项目中关于某个序列化类的class结构就无法保证一致,因此遇到class结构不一致时,会根据具体的差异情况,选择不同的处理结果。
以上述的Book对象为例,在消费者服务简称A、在提供者服务简称B,内容不一致时,RPC调用的反序列化结果:
| 差异场景 | 处理方式 |
|---|---|
| A和B的serialVersionUID不同 | InvalidClassException异常 |
| A和B的class全限定名不同 | ClassCastException异常 |
| A将id类型改为String | ClassCastException异常 |
| A将name改为bookName | 序列化后,实例B的name为null |
| A删除author属性 | 序列化后,实例B的author为null |
| B删除author属性 | 无影响 |
| A删除id的get方法,B删除id的set方法 | id赋值无影响 |
2.5 serialVersionUID作用
当对象实现Serializable接口后,可以手动声明一个serialVersionUID静态常量(不强制),并且在序列化时会记录到流中,反序列化时进行对比,如果不一致则序列化失败。这里建议手动声明,如果没有显示声明,jvm在序列化时也会参考内部结构基于算法生成一个,然而不同的jvm算法规则不一样,就存在反序列化失败的可能。
既然手动声明了,这个值就是固定的,又有什么意义呢?首先在RPC场景中,Consumer和Provider可能由不同的人维护,Provider可能会对DTO参数进行修改,比如添加一个属性,如果这个属性无关紧要,直接添加完发布就好了,就当Consumer调用时没有传这个属性,实现版本兼容。
如果这个属性非常重要,要求Consumer必须知道它的存在,那么Provider可以将serialVersionUID值+1,这样Consumer在调用后肯定异常,因为Provider反序列化参数肯定失败,迫使维护者必须更新自己的DTO,实现版本升级。