1.概述 Java传统IO是指java.io包中,以InputStream、OutputStream及其子类为代表的字节流 ,和Reader、Writer及其子类为代表的字符流 ,外加其他辅助类(文件类、异常类等)为基础,通过对操作系统函数的封装,形成的一套对IO设备的读写功能。
java.io包是Java提供最早的IO处理类,无论是字符流还是字节流,均通过同步阻塞 的方式读写数据,也就是我们经常说的BIO,因此可以将java.io包视为传统IO。
2.流的基础知识 2.1 流对象到底是什么? 简单说Java中的流对象就是一个传送带 ,传送带的一端连接操作系统内核,另一端连接我们的Java业务代码。Java项目作为运行在操作系统上的应用程序,是无法直接访问IO设备的,当我们想要从磁盘等地方读写数据时,只能通过调用内核函数来间接操作,流的作用就是封装内核调用等底层复杂操作,帮助开发者实现数据在内核和业务代码之间传送。
以文件读写为例,当我们想要从本地磁盘读取数据时,需要创建一个传送带(FileInputStream)并指定文件的路径,二进制数字就可以从内核不断的流向Java应用程序:
2.2 流的方向 流按照方向可分为输入流 、输出流 ,这种划分是站在内存角度去定义的。数据从IO设备流向内存的过程就是流的输入过程,例如InputStream、Reader的子类,用于应用程序从设备读取数据;数据从内存流向IO设备的过程就是流的输出过程,例如OutputStream、Writer的子类,用于应用程序向设备输出数据。
由此可以看出传统IO类的读写是单向的,输入流只能读取数据,输出流只能写入数据,读取和写入需要创建不同的流对象去完成:
2.3 流的单位 流按照单位可分为字节流 、字符流 ,字节流就是所有的IO操作都基于字节,字节流就是所有的IO操作都基于字符。对于字节流来说很好理解,因为所有的IO设备都只认二进制值,字节就是由8个二进制值组成的。而字符与二进制值不存在直接的关系,因此Java中每个字节流在创建的时候必须指定一个编码集,用于维护二进制值与字符的关系。
如果你读写的内容完全来自于ASCll表(美国信息互换标准代码) 包含的符号组成,那么字节流就可以完成读写功能,因为ASCll表中的符号可以用0到127来表示,单个字节就可以表示一个符号,每读取一个字节都可以按照ASCll表转化为符号,每写入一个字节先通过ASCll表转化为字节再写入。
如果你读写的内容包含汉字 、特殊符号 (♬、✿、★、♨等),单个字节是无法进行表示的,必须借助编码集实现。每个编码集都有一个映射表,用于记录哪几个字节值代表哪个汉字或特殊符号,例如UTF-8编码集中,汉字‘云’ 对应的编码为‘云’ ,编码的每个符号在ASCll表都存在,那么汉字就可以借助编码集顺理成章的转化为多个字节,因此你可以理解为字符流是对字节流的封装。
2.4 流的处理类型 流按照是否与IO设备直接连接,可分为节点流 、处理流 。节点流就是直接指定一个地点(磁盘、内存条等)进行读写,处理流并不直连IO设备,而是采用装饰器模式对节点流进行包装,在对外提供的方法不变的前提下,对原有功能进行增强。
以FileInputStream和BufferedImputStream为例,FileInputStream属于节点流,因为它指定文件路径后就可以直接读取,而BufferedImputStream是对它的装饰包装,当调用BufferedImputStream的read方法读取一个字节时,内部调用FileInputStream的read方法读取8192个字节将缓冲区填满,后续再读字节时就可以直接从缓冲区返回,直到内存读完。这样就减少了和操作系统的IO次数,实现对read方法的增强。
2.5 随机/顺序读写 暂无
3.字节流 InputStream是所有字节输入流的顶层类,定义了从IO设备读取字节到内存的一些基本、抽象方法:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 public abstract class InputStream implements Closeable private static final int MAX_SKIP_BUFFER_SIZE = 2048 ; public abstract int read () throws IOException public int read (byte b[]) throws IOException return read(b, 0 , b.length); } public int read (byte b[], int off, int len) throws IOException } public long skip (long n) throws IOException } public int available () throws IOException return 0 ; } public void close () throws IOException public synchronized void mark (int readlimit) public synchronized void reset () throws IOException throw new IOException("mark/reset not supported" ); } public boolean markSupported () return false ; }
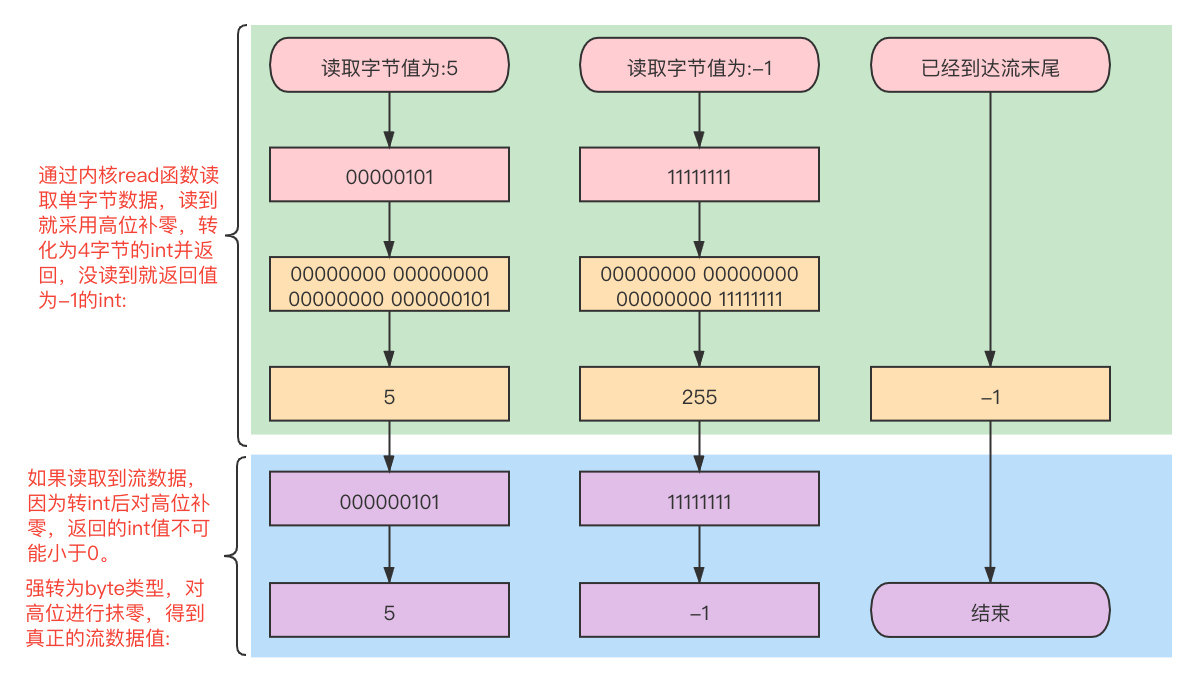
① read()方法明明是读取一个字节,为什么返回值是int类型呢?
至于Linux为什么不用null来表示已读完,可能是因为POXIS规范吧。Linux采用高位补零的方式将读取的byte值转化为int并返回,因此无论读取的字节值是多少,再高位补零后永远不可能是负数,当字节已经读到末尾时再读取则返回-1。在Java代码中拿到int值需要高位抹零(int转byte)得到真正的字节值:
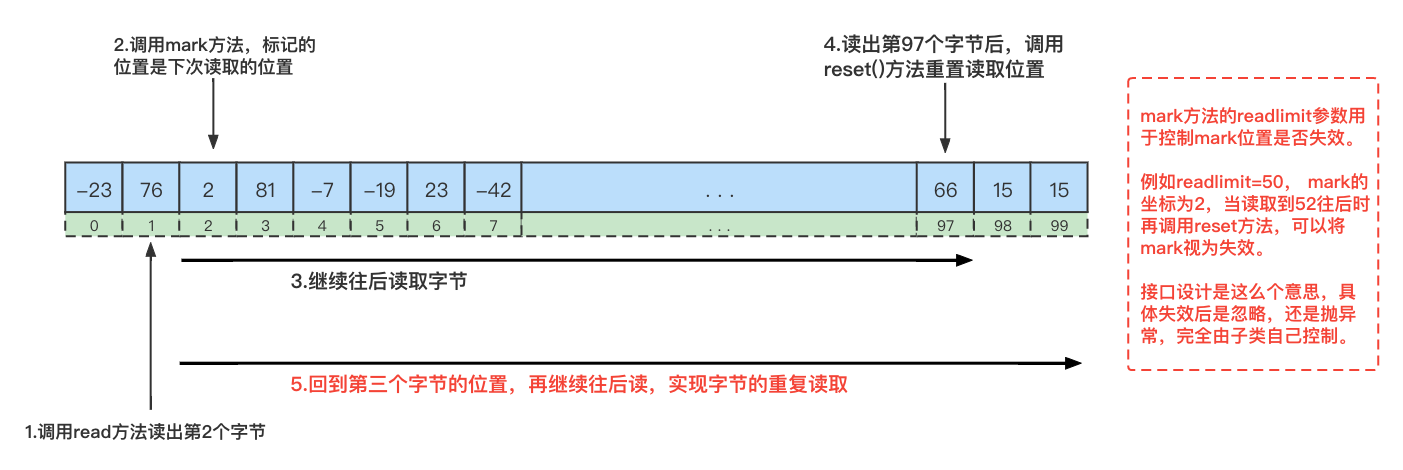
② 字节流如何重复读取数据?
③ 流为什么要关闭?
3.2 OutputStream OutputStream是所有字节输出流的顶层类,定义了向IO设备写入字节的一些基本、抽象方法:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 public abstract class OutputStream implements Closeable , Flushable public abstract void write (int b) throws IOException public void write (byte b[]) throws IOException write(b, 0 , b.length); } public void write (byte b[], int off, int len) throws IOException } public void flush () throws IOException } public void close () throws IOException }
输出流相比较输入流要简单很多,flush()方法的作用是刷新输出流,或者说清空输出流,这个清空不是直接删掉,而是把它挪到该去的地方。很多带缓冲概念的子类会重写这个方法,将缓存的数据手动刷回对应的IO设备中,例如常用的BufferedOutputStream。不存在缓存概念的例如FileOutputStream、ByteArrayOutputStream等就不会重写,因为没地方可以刷。
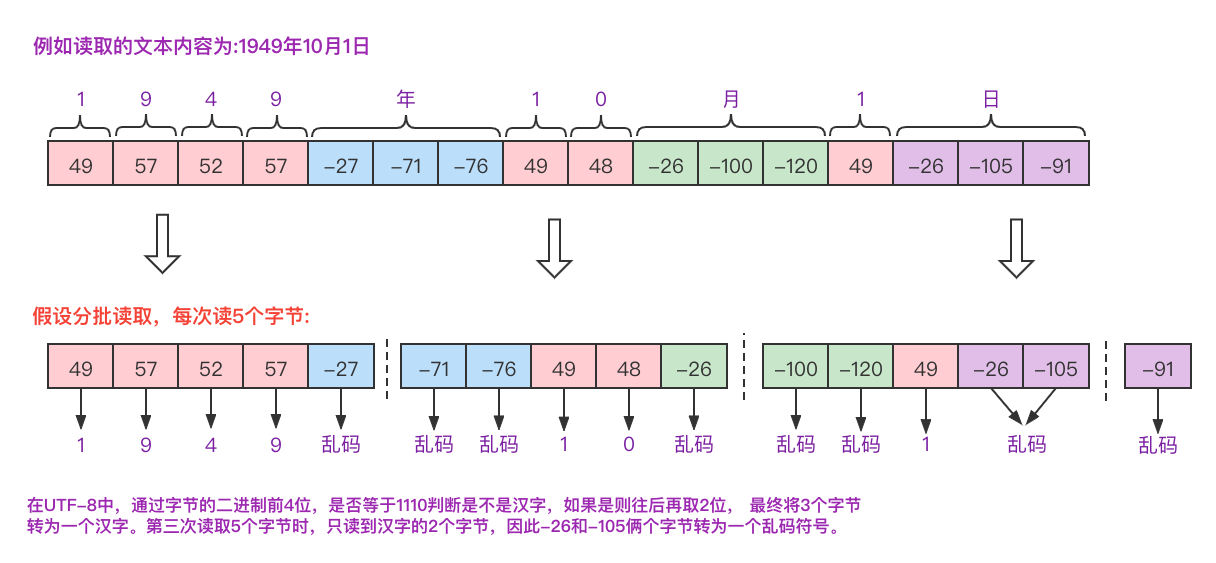
3.3 汉字处理 我们经常说读取中文内容需要用字符流,使用字节流会出现乱码。首先,只要包涵中文的内容,无论读还是写都必定会涉及到字符集 ,其次字节流并不是每次读取包含汉字的内容,都会出现乱码,要分情况看待。
例如使用文件字节流FileInputStream完成对中文内容进行读取,需要一次性读取整个文件的所有字节,并将结果存入某个字节数组中,最后手动指定字符集 转化为String:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 public class Main public static void main (String[] args) throws Exception FileInputStream fileInputStream = new FileInputStream("/Users/lvtao/Downloads/test" ); byte [] bytes = new byte [fileInputStream.available()]; fileInputStream.read(bytes); String result = new String(bytes, "UTF-8" ); System.out.println(result); fileInputStream.close(); } }
输出流执行写入操作仍然避免不了字符集,只不过String的getBytes方法使用操作系统默认字符集而已。总的来说字节流没有字符集的概念,也不关心读写的内容到底有没有汉字、特殊符号,所有操作只认字节。因此面对包含汉字的内容,要么手动处理字节和汉字的转化(可能乱码),要么使用字符流解决。
4.字符流 字符流与字节流的不同之处在于,字符流每次读取至少是一个字符 ,这个字符可能是数字、字母、特殊符号、汉字等,但绝对不会出现字节流那种,把一个汉字或特殊符号对应的多个字节拆成多分的情况,因此字符流没有乱码这一说(前提读和写使用的是同一种编码集)。
4.1 Reader 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 public abstract class Reader implements Readable , Closeable protected Object lock; protected Reader () this .lock = this ; } protected Reader (Object lock) if (lock == null ) { throw new NullPointerException(); } this .lock = lock; } public int read (java.nio.CharBuffer target) throws IOException } public int read () throws IOException } public int read (char cbuf[]) throws IOException return read(cbuf, 0 , cbuf.length); } abstract public int read (char cbuf[], int off, int len) throws IOException private static final int maxSkipBufferSize = 8192 ; private char skipBuffer[] = null ; public long skip (long n) throws IOException } public boolean ready () throws IOException return false ; } public boolean markSupported () return false ; } public void mark (int readAheadLimit) throws IOException throw new IOException("mark() not supported" ); } public void reset () throws IOException throw new IOException("reset() not supported" ); } abstract public void close () throws IOException }
4.2 Writer 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 public abstract class Writer implements Appendable , Closeable , Flushable private char [] writeBuffer; private static final int WRITE_BUFFER_SIZE = 1024 ; protected Object lock;protected Writer () this .lock = this ; } protected Writer (Object lock) if (lock == null ) { throw new NullPointerException(); } this .lock = lock; } public void write (int c) throws IOException synchronized (lock) { if (writeBuffer == null ){ writeBuffer = new char [WRITE_BUFFER_SIZE]; } writeBuffer[0 ] = (char ) c; write(writeBuffer, 0 , 1 ); } } public void write (char cbuf[]) throws IOException write(cbuf, 0 , cbuf.length); } abstract public void write (char cbuf[], int off, int len) throws IOException public void write (String str) throws IOException write(str, 0 , str.length()); } public void write (String str, int off, int len) throws IOException synchronized (lock) { char cbuf[]; if (len <= WRITE_BUFFER_SIZE) { if (writeBuffer == null ) { writeBuffer = new char [WRITE_BUFFER_SIZE]; } cbuf = writeBuffer; } else { cbuf = new char [len]; } str.getChars(off, (off + len), cbuf, 0 ); write(cbuf, 0 , len); } } public Writer append (CharSequence csq) throws IOException if (csq == null ) write("null" ); else write(csq.toString()); return this ; } public Writer append (CharSequence csq, int start, int end) throws IOException CharSequence cs = (csq == null ? "null" : csq); write(cs.subSequence(start, end).toString()); return this ; } public Writer append (char c) throws IOException write(c); return this ; } abstract public void flush () throws IOException abstract public void close () throws IOException }
4.3 汉字处理 常用的字符流中,除了CharArrayReader、CharArrayWriter这俩实现类,完全就是在内存中读写字符,根本不会涉及和字节的转换,其他实现类的最底层都是对StreamEncoder、StreamDecoder类的装饰。
这俩个类内部又是对InputStream、OutputStream的装饰,因此是最接近字节流的字符流 。每次调用InputStream的read方法后,会将字节解码成汉字再返回。每次写入包含汉字的内容时,会编码成字节在调用OutputStream的write方法。
StreamEncoder与StreamDecoder的底层通过Charset对象,完成对汉字、特殊符号的读写。我们可以写个Demo看看Charset是怎么处理汉字的:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 public static void main (String[] args) throws Exception Charset charset = Charset.forName("UTF-8" ); CharsetEncoder encoder = charset.newEncoder(); String text = "1949年10月1日,中华人民共和国成立" ; CharBuffer charBuffer = CharBuffer.wrap(text.toCharArray()); ByteBuffer encodeByteBuffer = encoder.encode(charBuffer); CharsetDecoder decoder = charset.newDecoder(); CharBuffer decoderCharBuffer = decoder.decode(encodeByteBuffer); System.out.println(decoderCharBuffer.toString()); }
Charset对象本质上就是对操作系统的字符集功能进行封装,Java中创建一个字符流对象需要指定一个字符集,并且会调用操作系统函数,检查字符集名称存不存在,如果没有指定,会使用当前操作系统的默认字符集。