IO流(一) Linux系统中的IO
1.概述
Java的各种IO流对象,都是在操作系统提供的IO功能基础上进行设计的,因此越过操作系统去研究Java的IO流有点不切实际,通常我们的服务都是部署在Linux系统中,因此研究Linux中的IO原理,是学习Java IO流的基础。
2.驱动程序
2.1 什么是驱动程序
驱动程序是比操作系统更为底层的技术,也是最接近硬件的软件,换句话说就是连接硬件和操作系统的桥梁,它的主要作用是驱动各种硬件完成自身支持的功能。
以最常用的Window系统为例,重装系统后需要通过鲁大师、驱动精灵等装网卡、显卡等驱动,否则无法连接网络、无法玩LOL等网络游戏。以MacOS为例,连接有线网需要购买转接头,并下载对应厂商提供的转接头驱动程序,否则无法连接。
2.2 与linux关系
计算机中有很多硬件,以硬盘为例,又可分为机械硬盘和固态硬盘,每种类型的硬盘又有不同的厂商生产出不同的版本型号,其中每一种情况都可能对应一个驱动软件。而Linux系统在设计IO子系统时不可能将所有情况都考虑并进行兼容,因此在内核提供了一套驱动开发标准,硬件厂商依据此标准开发自己的驱动软件,使用者需要根据对应的硬件下载对应驱动程序,
Linux系统通过对驱动的调用,完成对IO设备的控制。
因此驱动程序说直白点就是对硬件进行抽象,屏蔽了同一类型硬件但不同版本型号的差异,并提供统一标准API给Linux内核调用,如图: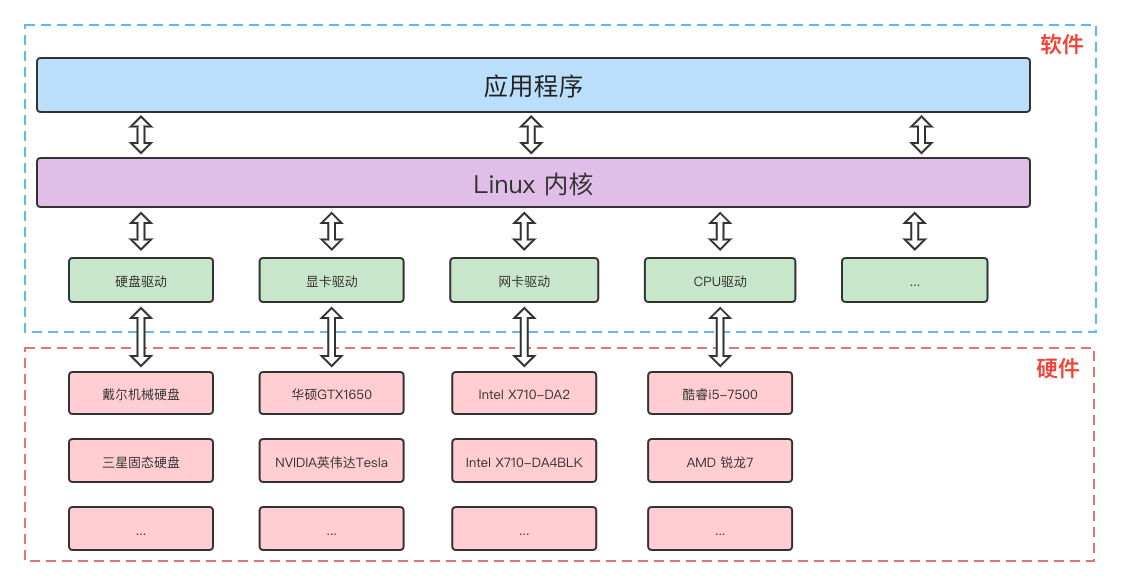
3.虚拟文件系统
驱动程序虽然摒弃了同一硬件类型不同版本型号的差异,但是不同的硬件在调用层面仍然有差别,而Linux系统通过一切皆文件的设计理念,将所有硬件设备抽象成文件子系统,硬盘、网卡等设备都会实现文件子系统的标准接口,然后通过虚拟文件系统对应用程序进行呈现: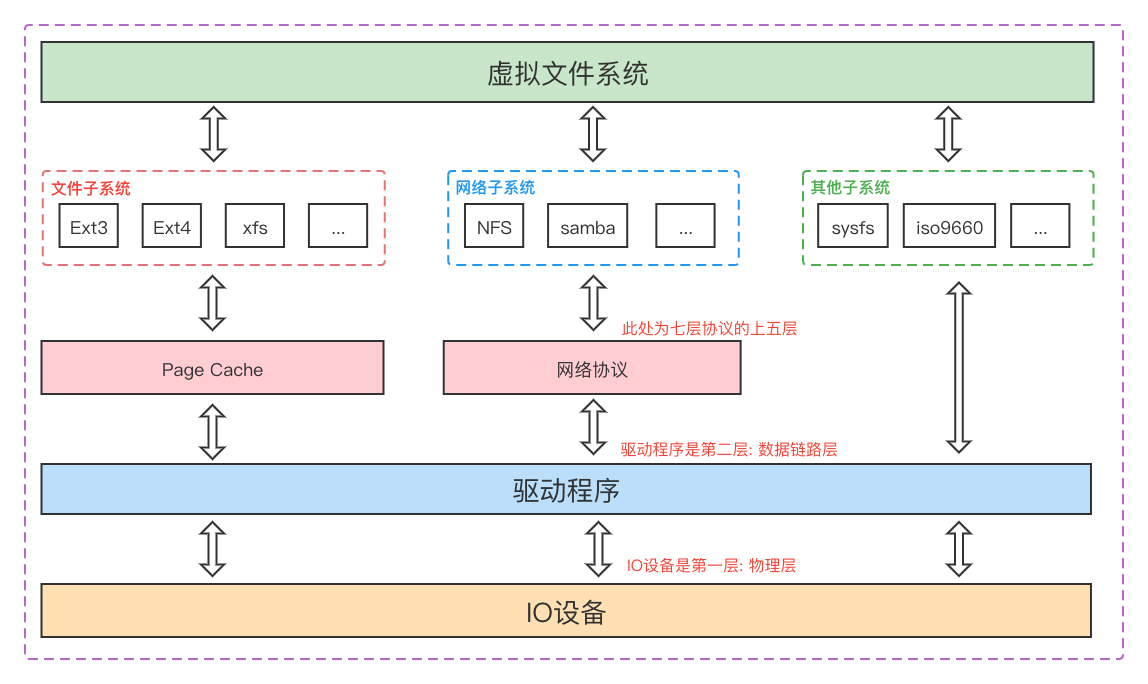
Linux系统虽然将一切看作都文件,但又将文件这个抽象概念分成普通文件、目录文件、链接文件和设备文件,不同的类型提供的操作类型也不同,例如设备文件不能像普通文件那样支持复制、粘贴等功能。
3.1 文件子系统
暂无
3.1 网络子系统
暂无
3.1 其他子系统
4.文件描述符
在linux系统中,设备也是以文件的形式存在,要对该设备进行操作就必须先打开这个文件,打开这个文件就会获得这个文件描述符,它是个很小的正整数,可以看作是一个索引值,指向内核为每一个进程所维护的、该进程打开文件的记录表。
4.1 描述符结构
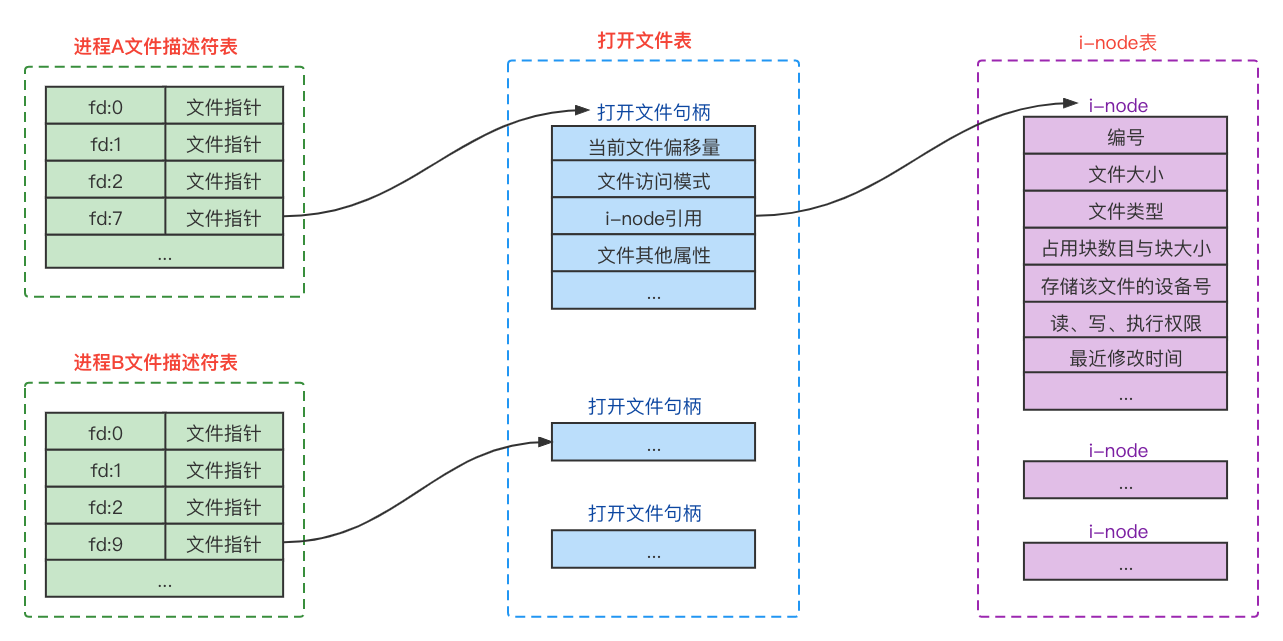
首先每个进程都有一张文件描述符表,用于记录此进程打开的文件,同一个文件可能会被不同的进程打开,也有可能会被同一进程的不同线程打开,总之每次打开得到的都是不同的文件描述符。同时Linux会对每个进程的打开文件数进行限制,一般是1024个(可以通过命令修改)。
每个文件描述符在打开文件表都对应一个打开文件句柄,这个句柄记录了此次打开的一些状态信息,这里重点说下关联操作属性(file_operations),此属性作为指针指向一张函数操作表,函数操作表中有当前文件支持的所有操作函数。普通文件、设备文件等不同类型的文件,指向的函数操作表也不同,因此通过这个属性可以将不同类型的文件的操作区分开。
i-node表维护了文件的具体信息,每个文件在被进程打开后都会将结构信息加载到i-node表中,如果一个文件被多次打开也只会加载一次,与打开文件句柄是一对多的关系。也就是说应用程序通过内核函数操作文件时,都是基于i-node进行操作。
4.2 标准描述符
| 描述符 | 名称 | 对应设备 |
|---|---|---|
| 0 | 标准输入流 | 键盘 |
| 1 | 标准输出流 | 显示屏 |
| 2 | 标准错误流 | 显示屏 |
当我们在Linux环境中启动一个进程,会自动向此进程的文件描述符表中添加这三个描述符(值固定),换句话说,进程如果想要对键盘、显示屏进行IO操作,是不需要手动打开的,Linux系统已经帮我们准备好了。
例如使用nohup命令运行Java包时,会在命令后添加xxx.log 2>&1,这个后缀的意思就是将标准错误输出重定向到标准输出流、然后将标准输出流重定向到xxx.log文件,说白了就是让java的日志或print输出到指定的日志文件。
4.3 指针移动
在文件描述符对应的打开文件句柄中,有个当前偏移量属性,记录了文件读写操作的位置。以读取为例,假设某个文件共2000个字节,初始偏移量就是0,每读取一个字节就将偏移量值加1,读取n个字节就将偏移量加n,直到偏移量递增到1999(从0开始偏移)为止读取结束,后续再调用返回结束标志:
5.IO函数
5.1 open
open函数是最基本的函数,打开一个文件或设备,如果打开成功则返回一个文件描述符值,失败则返回-1。有了文件描述符值就可以对文件或设备进行操作:
1 |
|
Linux的/dev目录存放了与设备相关的文件,如果你想open一个打印机、键盘、网卡等硬件设备,需要到此目录找到对应的文件,然后将文件路径作为参数传入即可。
5.2 socket
socket函数与open函数一样用于获取描述符,由于网卡相对其他设备较为特殊,需要额外考虑到IP类型、传输协议等,因此open函数无法满足,需要通过socket函数生成一个套接字描述符(文件描述符的一种):
1 |
|
protofamily与type确定的情况下,可以决定最终的传输协议,但是这俩者组合后可能衍生一或多个传输协议,也可能一个都没有。如果衍生出多个传输协议,就需要通过protocol参数进行补充,说白了就是告诉操作系统具体用哪个;如果仅衍生出一个,protocol参数填0即可;如果一个都没衍生出来,操作系统会选择type默认的传输协议。无论衍生出什么组合,只要protocol参数传入0,那么操作系统都会选择type默认的传输协议。
这里虽然得到了套接字描述符(sockfd),但一个服务器可能运行很多个进程,多个进程共享一个网卡硬件完成网络数据的收发,因此无论是服务端还是客户端,必须使用bind函数为此sockfd绑定ip(IPv4、IPv6等)和端口,实现各进程的网络数据传输隔离。
此时sockfd仍然不知道能和谁通信,因此还得调用listen函数对此sockfd进行监听,如果某个客户端进程(可能本机,也可能远程机器)调用connect函数并指定ip和端口进行连接,服务端的listen函数会监听到连接请求,然后通过accept函数对连接请求进行处理,并返回一个acceptfd。
linux中服务端和客户端是一对多的关系,accept函数提供于服务端,因为服务端需要知道并区分每一个客户端的连接,因此返回值acceptfd就是标记与每个客户端的连接通道。connect函数提供于客户端,因为一个客户端只能对应一个服务端,所以客户端在连接过程中不会生成新的描述符。
如果客户端想要连接多个服务端,那就要手动创建新的sockfd,但ip端口已经被原来的sockfd占用,不同的sockfd绑定同一个ip端口会报错,这时候就得使用端口复用技术,允许某个进程的多个sockfd绑定到某一个ip端口上。绑定成功后再调用connect函数,基于新创建的sockfd与服务端进行连接。
假设服务端和客户端建立的是TCP连接,那么从客户端调用connect函数,到服务端执行accept函数的过程,就是三次握手的过程: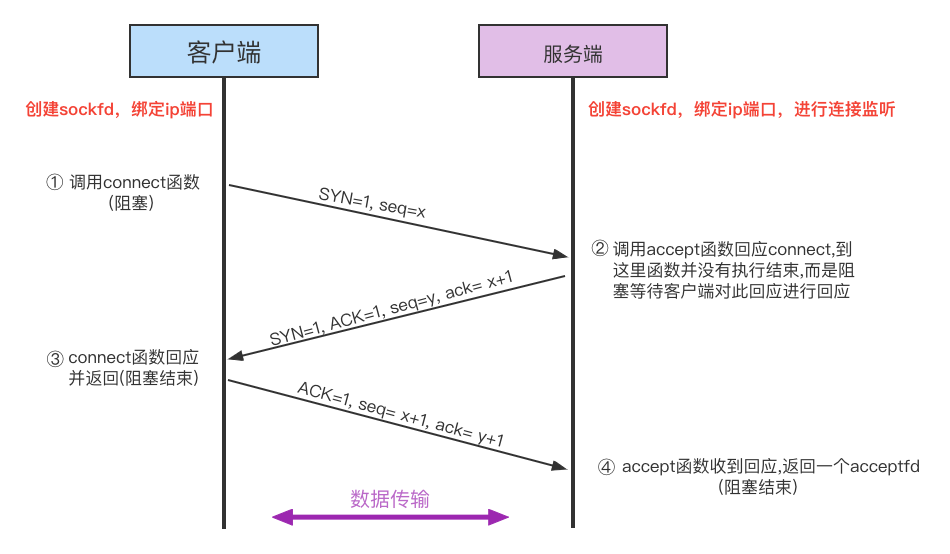
5.3 read与write
1 |
|
就单纯的对描述符对应的文件进行读写,读写成功后会触发文件描述符的指针移动。以读取为例,假设最后读取了10个字节,那么读取后需要将指针(也可以理解为读取进度)往后移动10位,确保下次读取不会对同一位置的字节重复读取。
以写入为例,假设最后写入了10个字节,也要将指针往后移动10位,确保下次写入接着上次的位置往后写,不会对同一位置重复写,覆盖之前的write操作。
5.4 send与recv
1 |
|
5.5 close
1 |
|
6.IO模型
6.1 同步阻塞IO
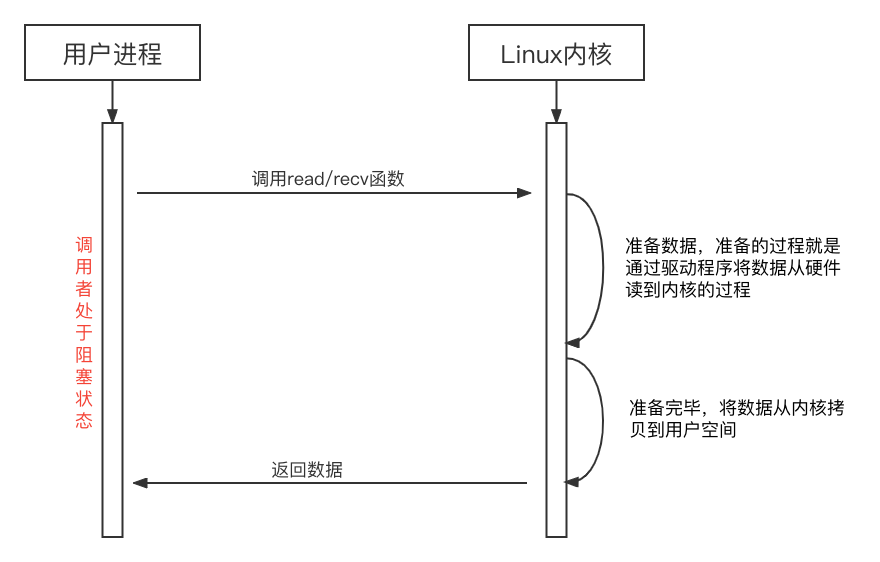
同步阻塞IO就是应用程序在调用内核函数过程中一直处于等待状态,不能执行其他任何操作,直到内核将数据返回后,才能继续往后执行代码。同步阻塞在磁盘IO和内存IO中使用较为广泛,因为硬盘和内存总会快速读取(大文件除外),同步阻塞实现起来简单明了,非阻塞或者异步只会让设计更复杂,却又对性能没多少帮助。
6.2 同步非阻塞IO
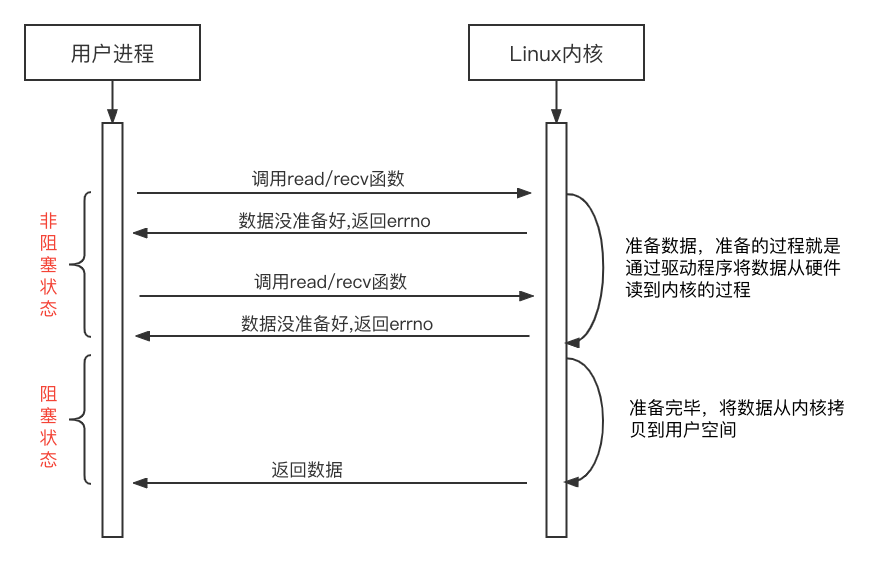
同步非阻塞IO在数据没有准备好时总会快速返回errno,当数据准备好时才会进入阻塞,直到拷贝到用户空间并返回。这种方式可以让应用程序在进行IO操作时更加灵活,当读取的文件较大或者等待网络请求时,可以利用准备数据的这段时间处理其他逻辑,提高任务的执行效率,直到数据准备完毕后再次调用,阻塞并等待数据拷贝返回。
6.3 IO多路复用
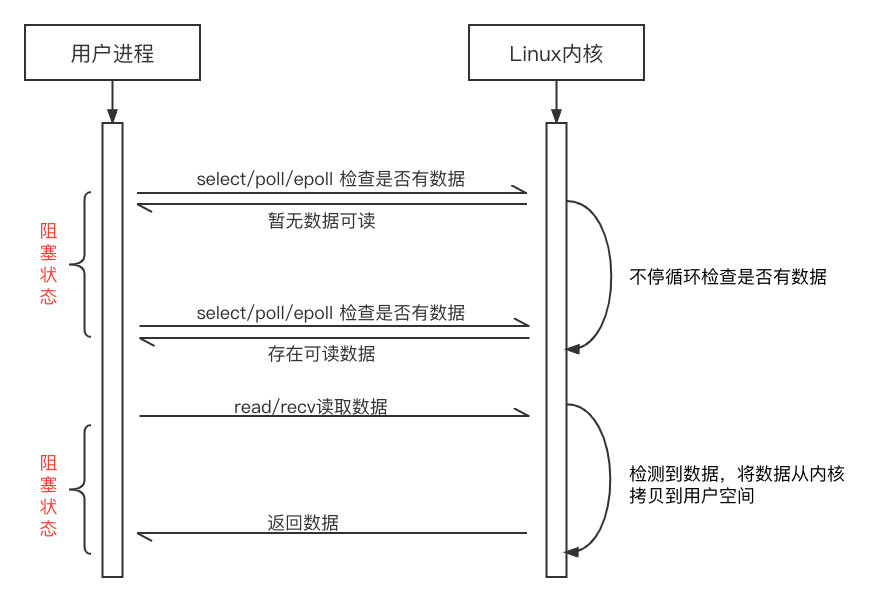
IO多路复用模型常用于网路IO,解决服务端和客户端TCP并发连接数高、网络交互不频繁的场景,假设现在用同步(阻塞或非阻塞)的方式处理客户端的网路IO,由于服务端不知道客户端什么时候会发送数据,上面也有讲过每个连接都会分配一个描述符,因此对于每个连接都需要分配一个线程不停的去检查,检测到请求就及时响应。如果连接较少就无所谓了,当连接数达到1W甚至更多,那么就会有1万甚至更多个线程不停的循环检查数据,CPU直接就炸了。
上述的问题就是服务端经典的C10K问题,本质上是操作系统的问题。IO多路复用采用单线程监听多个客户端网络请求的方式,将多个连接客户端的sockfd放入一个集合中,然后交给某一个线程去轮询这些连接,当发现某个sockfd传来数据时就通知服务端处理,避免大量的线程轮询忙等带来的CPU浪费。由此也可以看出此模型不适合磁盘,因为磁盘IO不像网路IO那样不知道啥时候会有数据传来,磁盘的数据就摆在那读完就结束了。
Linux系统提供了select、poll、epoll三种IO多路复用机制,虽然都是通过单个线程监听多个描述符,但内部监听的方式不同、存储sockfd的数据结构不同、对sockfd的数量限制也不同,下面单独讲。
6.4 信号驱动IO
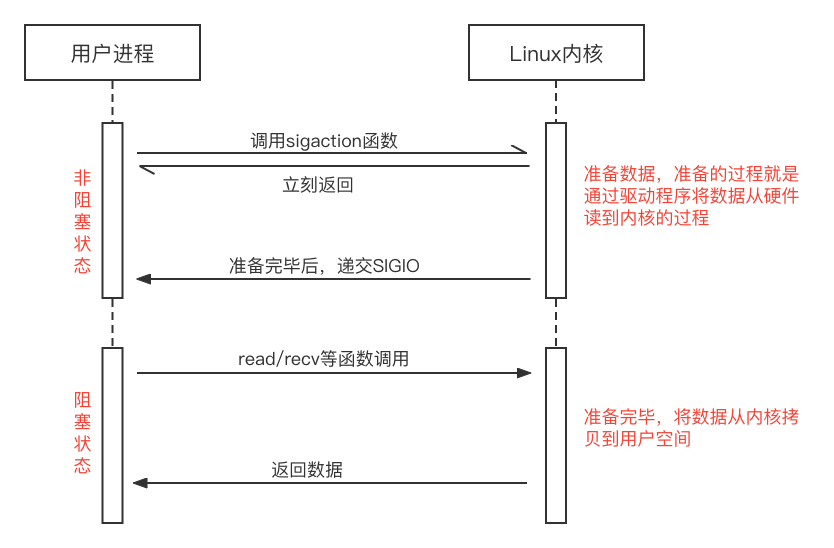
信号驱动IO模型底层采用中断机制,对IO设备进度读取时立刻返回(非阻塞),Linux系统中用sigaction函数将SIGIO读写信号以及handler回调函数存在内核队列中。当设备IO缓冲区可写或可读时触发SIGIO中断,返回设备fd并回调handler。与其他同步非阻塞IO模型相比,信号驱动IO模型在准备数据阶段不需要应用程序主动轮询检查,因此更节约CPU资源。
使用kill -l命令,可查看Linux系统支持的信号量列表(SIGIO的编号为29):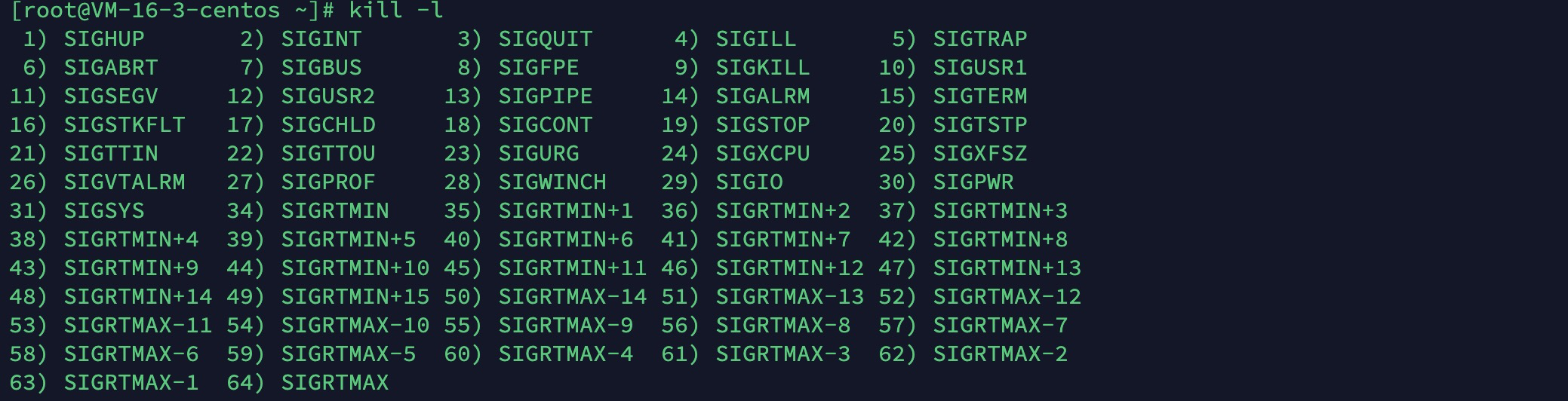
其中编号为1 ~ 31的信号为传统UNIX支持的信号,是不可靠信号,编号为32 ~ 63的信号是后来扩充的,称做可靠信号。不可靠信号和可靠信号的区别在于前者不支持排队%},例如同一个可靠信号量发送多次到某个进程,内核可以缓存最多8192个(版本不同会有差异);例如同一个不可靠信号量发送多次到某个进程,内核只会缓存一个,多余的信号量直接丢弃。
SIGIO信号量在TCP连接中支持的IO事件:
- 监听的套接字上有新连接请求完成
- 某个断开连接请求发起
- 某个断开连接请求完成
- 数据到达套接字
- 数据已从套接字发送走
- 发生某个异步错误
SIGIO信号量在UDP连接中支持的IO事件:
- 数据报到达套接字
- 套接字上发生异步错误
信号驱动IO模型最大的缺点,是使用SIGIO信号量时无法识别IO事件的具体类型,特别是TCP这种属于双向可靠连接,可产生信号的条件很多,而我们真正想要的只是连接完成和数据到达事件。这就导致TCP连接使用此模型时,会频繁的产生SIGIO信号,因此回调函数每次都要去检查是否有新连接、是否有可读数据,但并不是每次信号都需要真正的处理网络请求。
如果服务端与1W个客户端建立TCP连接(C10K问题),每一个TCP通道都会分配一个handler用于接收SIGIO信号,由于TCP的SIGIO信号量产生过于频繁,这些handler的回调函数,相当一部分时间里都是在检查是否有新连接、是否有可读数据,而只有少数时间是真正的处理网络请求,反而更浪费CPU资源。
而UDP是无状态的连接,只有数据到达套接字、发生错误这俩种情况才会产生信号,每次产生信号都是有任务需要处理,回调函数的逻辑判断也简单很多。因此信号驱动IO模型在UDP连接中使用较多,而TCP极少使用。
6.5 异步非阻塞IO
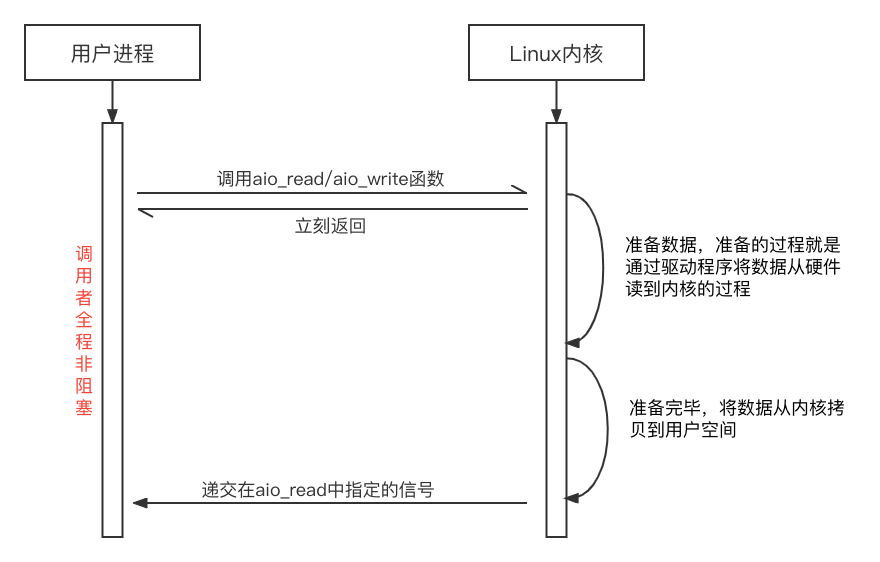
以上四种IO模型都属于同步IO模型,同步阻塞IO模型全程处于阻塞状态,同步非阻塞IO模型、信号驱动IO模型在数据copy阶段仍然阻塞,因此不能说是异步;IO多路复用在轮询过程中也处于阻塞状态。只有异步非阻塞IO模型才是完完全全的异步模型。
Linux从2.6版本开始支持异步IO,此功能最初是为数据库设计的,因此通过异步IO的读写操作不会被缓存或缓冲,这就无法利用操作系统的缓存与缓冲机制。
7.IO多路复用函数
7.1 select
1 | int select (int nfds, fd_set *readfds, fd_set *writefds, fd_set *exceptfds, struct timeval *timeout); |
参数介绍
- nfds: 需要监视的最大的文件描述符值+1
- readfds: 要监听的读文件描述符
- writefds: 要监听的写文件描述符
- exceptfds: 要监听的异常文件描述符
- timeout: 超时设置,null表示没限制一直等、0表示扫描一轮立刻返回、指定值:扫描指定时间,直到超时
返回值
- 大于0: 表示多少个描述符就绪
- 等于0: 表示超时
- 小于0: 表示监控出错了(select本次监控出错)
执行流程图: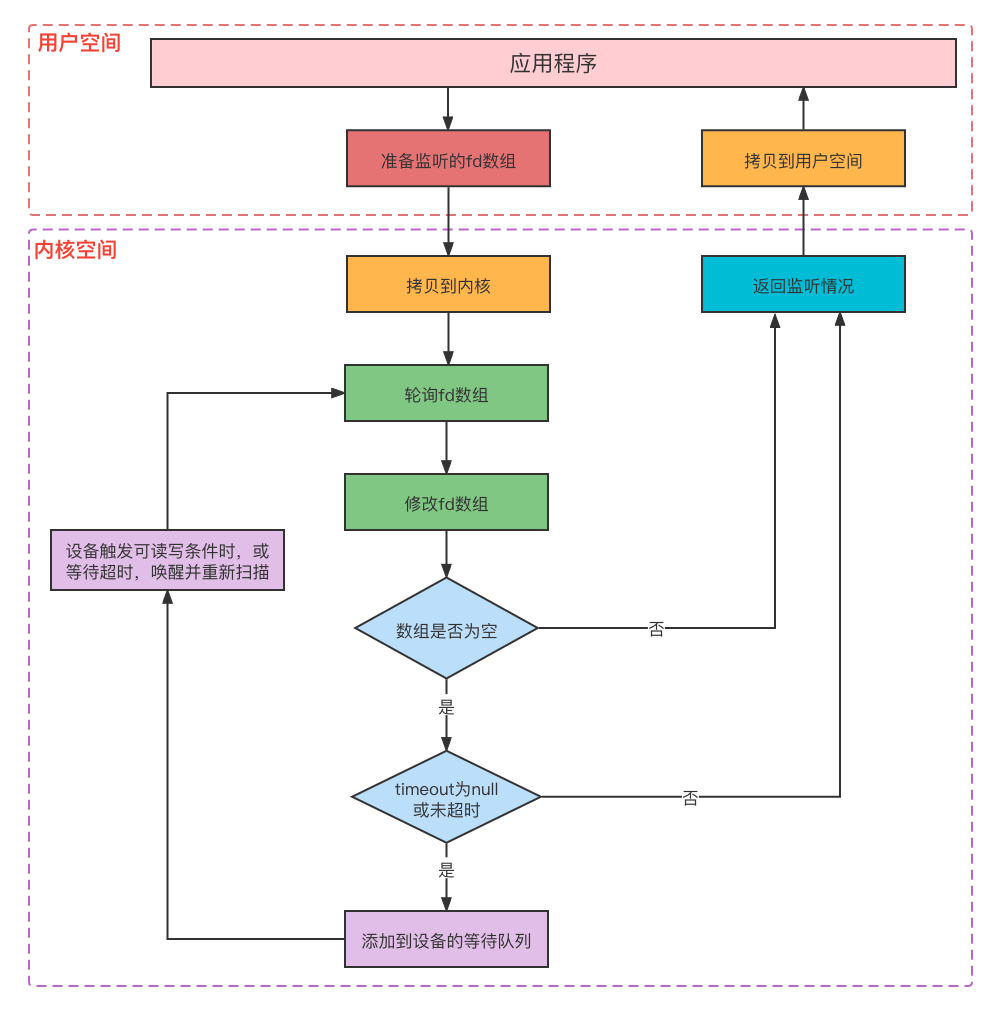
轮询时如果发现某个描述符没有就绪,那么会从数组中剔除,最终返回的集合中仅包含就绪的描述符,因此应用程序拿到数组后还需要进行遍历,才能确定哪些描述符是就绪的。如果timeout参数为null或特定值,那么会对数组多次轮询,因此在轮询前还会将数组copy一份,防止上次轮询无事件,导致数组被清空。
轮询毕竟会多余的消耗CPU资源,如果timeout参数为null或特定值,那么会对数组多次轮询,在进程没有从设备读到数据时,会进入设备的睡眠队列中(可设置睡眠时间),直到睡眠超时或设备发生读写事件提前唤醒,再次进入下次轮询,减少对CPU无意义的消耗。
select的工作模式为条件触发,函数将存在事件的描述符数组返回给应用程序时,如果应用程序对某个描述符不作任何处理,那么之后的轮询仍然会返回此描述符,直到对此描述符进行处理为止。
7.2 poll
使用链表存储监听的描述符,对监听的描述符不作数量上的限制,其他与select一致。
7.3 epoll
epoll在2.6内核中提出,主要为了解决select和poll的缺点,比前两者更灵活但实现起来也更复杂。内部操作过程又可分为epoll_create, epoll_ctl、epoll_wait三个函数:
1 | // 创建一个epoll的句柄,用于存放需要监听的fd |
epoll_create函数用于创建一个epoll专用的fd集合,用于存储想要监听的描述符。参数size并不是限制了epoll所能监听的描述符最大个数,只是对内核初始分配内部数据结构的一个建议。
epoll_ctl函数是对epfd(epoll_create函数的返回值)进行相关操作,op参数代表操作类型(新增、修改、删除),event参数代表操作事件(可读、可写、挂断等)。例如指定某个epfd内部的某个fd,新增一个可读事件监听,新增成功返回0,失败返回-1。
epoll_wait函数用于等待epfd上的io事件,等待过程中线程阻塞。前俩个函数可以创建一个fd集合,并对其中的每个fd设置各种类型的监听事件,而此函数则真正负责监听。内核会把监听到的事件添加到events参数中,最多添加maxevents个,并通过timeout参数控制超时时间,返回监听到的事件数量。
epoll内部执行流程图: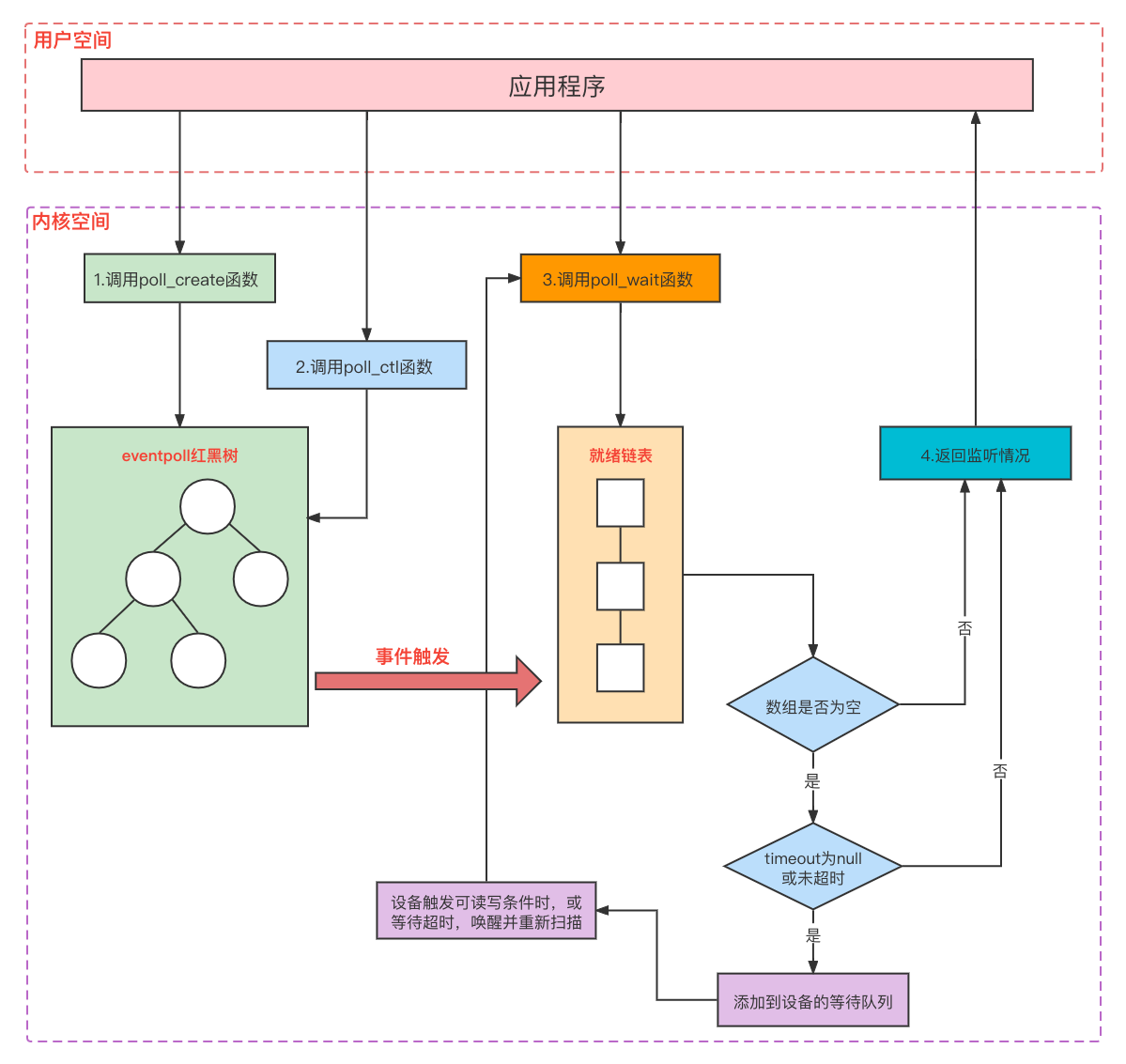
epoll不会像select那样对监听的描述符数量进行限制,也不会像select/poll那样每次监听都将所有fd传到内核,而是通过epoll_ctl函数逐个放入,后续调用epoll_wait函数监听时,只需要告诉内核epfd即可,达到数据轻量拷贝的效果,不过返回时仍然需要拷贝所有fd到应用程序。
epoll还使用了事件驱动的机制,在内核维护了一个链表记录就绪事件,当某个socket有事件发生时会向CPU发送中断信号,然后执行对应的回调函数将描述符添加到就绪链表中,应用程序通过epoll_wait函数获取就绪描述符时,只需要扫描这个链表即可,也就是说epoll只关心活跃连接,并不会像select/poll那样随着连接数增多,效率降低。
epoll支持条件触发(LT)和水平触发(ET)两种工作方式,LT的工作方式在写select时说的很清楚了。ET在就绪通知方面与LT相反,对于就绪的描述符仅通知应用程序一次,即使应用程序没有进行处理也不会在多次监听过程中重复提醒,除非你做了某些操作导致变成未就绪状态,后面再次就绪才会再提醒。ET模式在调用epoll_ctl函数时,在event参数的属性中设置。
从epoll的原理来看,好像比select/poll要高级很多,但这并不代表epoll能完全代替select/poll。对于监听的fd集合,如果每次检查大多数fd都处于就绪状态,使用事件驱动的机制就有点画蛇添足了,还不如直接轮询。因此epoll相对于select/poll来说,适合连接数更多、请求频率更低的场景。
8.零拷贝技术
零拷贝技术是Linux系统对IO性能的一种优化,让进程在整个IO操作过程中,用户内存与内核内存之间的拷贝次数降为零次,因此称为零拷贝技术。传统的IO操作,进程需要调用open()或socket()函数来确定IO的目标,并得到一个描述符,后续将这个描述符以及读写的内容作为参数,调用Linux内核函数进行读写:
由于内核内存与进程内存完全隔离,也就意味着每次IO操作,必须经历一次内核内存与进程内存之间的数据拷贝,对于大文件的读写,或者大数据量的网络请求接受,这个步骤是比较消耗资源的。Linux系统提供了mmap()、sendfile()函数来减少拷贝的次数,提高IO效率。
8.1 mmap()
1 | void *mmap(void *start, size_t length, int prot, int flags, int fd, off_t offset); |
了解Linux虚拟内存机制是掌握mmap()原理的基础,这里我省略不写了。在传统IO过程中,进程通过open()或socket()函数得到内核分配的描述符,但完全不知道描述符涉及到的物理地址在哪,内核函数会根据描述符找到对应的虚拟地址,经过CPU的MMU转化为物理地址再执行读写,也就是说底层的逻辑Linux已经帮我们封装好了,进程对于设备地址这些概念是透明的。
mmap()函数的作用,是在内核中初始化一块虚拟内存,内存大小和描述符对应的数据大小一致,一般都是针对磁盘文件。进程在调用此函数后,内核会将初始化的这块内存地址,映射到进程内存空间的某块虚拟地址上,并返回映射的地址值,这样进程就拥有了这部分内核内存的访问权:
进程拥有描述符对应的虚拟地址后,就不需要借助read()、write()等函数了,可以直接调用文件系统,甚至是块设备驱动的相关函数进行读写,从而减少用户内存与内核内存之间的拷贝。如果是写入的话,内核也能通过地址访问随时感知到数据的变化,并且在合适的时候将数据落盘(映射内存的读写经过PageCache):
8.2 sendfile()
1 | ssize_t sendfile(int out_fd, int in_fd, off_t *offset, size_t count); |
参数说明:
- out_fd: 已经打开的、传输过程中用于写入的描述符
- in_fd: 已经打开的、传输过程中用于读取的描述符
- offset: 从in_fd对应地址的哪个位置开始读取数据
- count: 从in_fd的offset位置开始,拷贝到out_fd的字节总数
返回值说明:
如果成功的拷贝,返回写操作到out_fd的字节数,错误返回-1,并相应的设置error信息。
sendfile()函数是专门针对不同描述符之间的IO传输,例如将某个file描述符的某段数据写入某个socket描述符,相对于mmap()来说使用场景可能少一点,但执行效率要高一些。下面是sendfile()函数的工作流程:
从图中可以看出,使用sendfile()函数进行IO传输,数据根本就不会经过进程内存,也就不存在内核与进程内存之间的数据拷贝,并且读写两个操作经历一次系统函数调用即完成,减少一次系统函数调用,也就意味着减少一次上下文切换。
8.3 使用场景
在使用场景方面,mmap()函数要比sendfile()函数广泛一些,首先mmap()函数可以单纯的读取或单纯的写入,也可以读写组合使用,sendfile()函数必须要指定两个描述符进行传输,而且sendfile()函数在整个IO操作过程中,进程完全不知道传输的数据内容是什么。以RocketMQ和Kafka为例:
RocketMQ使用mmap()方式,主要因为Consumer订阅消息支持过滤功能,每条消息都有关于tag的hashCode,Broker进程需要将消息从磁盘读取到进程内存中,然后通过hashCode判断这条消息是否需要过滤掉,因此无法使用sendfile()。
Kafka没有消息过滤功能,整个设计只注重吞吐量,因此在向Consumer发送消息时,完全不需要关注消息的内容,使用sendfile()性能最佳。但Producer进行消息写入时,只涉及到磁盘设备,Kafka使用了mmap()函数进行消息持久化。