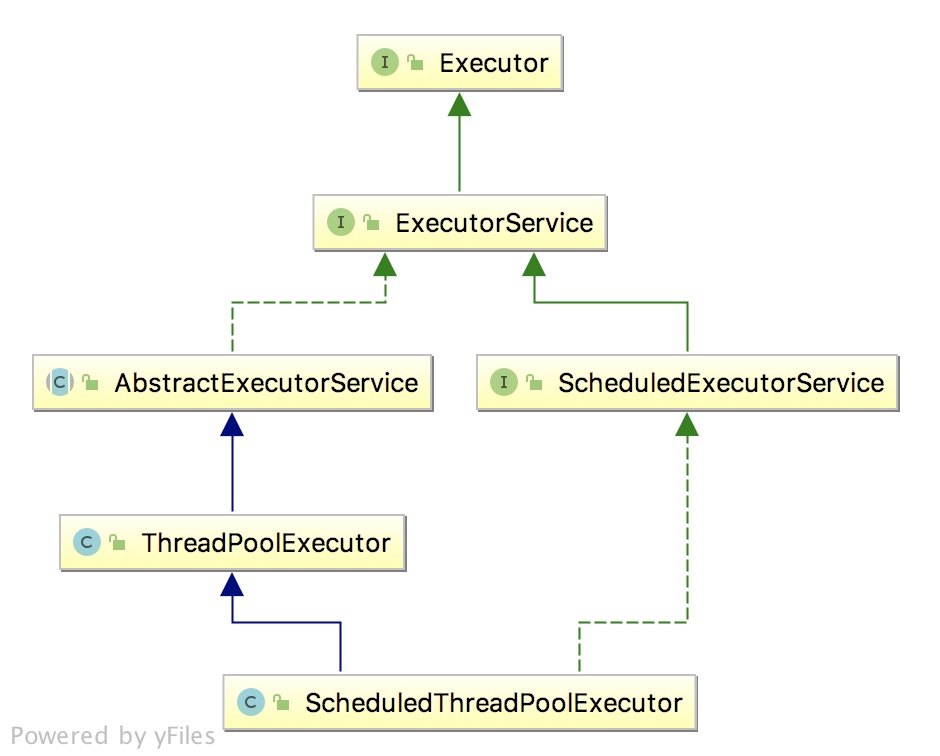
public interface ScheduledExecutorService extends ExecutorService {
// 在指定延时后执行一次 public ScheduledFuture<?> schedule(Runnable command, long delay, TimeUnit unit); // 在指定延时后执行一次 public <V> ScheduledFuture<V> schedule(Callable<V> callable, long delay, TimeUnit unit); // 在指定延时后开始执行,并在之后以指定时间间隔重复执行(间隔不包含任务执行的时间) // 无论任务是否完成,只要到时间就执行下一次 public ScheduledFuture<?> scheduleAtFixedRate(Runnable command, long initialDelay, long period, TimeUnit unit);
// 在指定延时后开始执行,并在之后以指定延时重复执行(间隔包含任务执行的时间) // 上次任务结束才开始倒计时,只可能一个线程在工作 public ScheduledFuture<?> scheduleWithFixedDelay(Runnable command, long initialDelay, long delay, TimeUnit unit); }
public class ThreadPoolExecutor extends AbstractExecutorService{ protected <T> RunnableFuture<T> newTaskFor(Runnable runnable, T value) { return new FutureTask<T>(runnable, value); }
protected <T> RunnableFuture<T> newTaskFor(Callable<T> callable) { return new FutureTask<T>(callable); }
public Future<?> submit(Runnable task) { if (task == null) throw new NullPointerException(); RunnableFuture<Void> ftask = newTaskFor(task, null); execute(ftask); return ftask; }
public <T> Future<T> submit(Runnable task, T result) { if (task == null) throw new NullPointerException(); RunnableFuture<T> ftask = newTaskFor(task, result); execute(ftask); return ftask; }
public <T> Future<T> submit(Callable<T> task) { if (task == null) throw new NullPointerException(); RunnableFuture<T> ftask = newTaskFor(task); execute(ftask); return ftask; }
private <T> T doInvokeAny(Collection<? extends Callable<T>> tasks, boolean timed, long nanos) throws InterruptedException, ExecutionException, TimeoutException { if (tasks == null) throw new NullPointerException(); int ntasks = tasks.size(); if (ntasks == 0) throw new IllegalArgumentException(); ArrayList<Future<T>> futures = new ArrayList<Future<T>>(ntasks); ExecutorCompletionService<T> ecs = new ExecutorCompletionService<T>(this);
try { // Record exceptions so that if we fail to obtain any // result, we can throw the last exception we got. ExecutionException ee = null; final long deadline = timed ? System.nanoTime() + nanos : 0L; Iterator<? extends Callable<T>> it = tasks.iterator();
// Start one task for sure; the rest incrementally futures.add(ecs.submit(it.next())); --ntasks; int active = 1;
for (;;) { Future<T> f = ecs.poll(); if (f == null) { if (ntasks > 0) { --ntasks; futures.add(ecs.submit(it.next())); ++active; } else if (active == 0) break; else if (timed) { f = ecs.poll(nanos, TimeUnit.NANOSECONDS); if (f == null) throw new TimeoutException(); nanos = deadline - System.nanoTime(); } else f = ecs.take(); } if (f != null) { --active; try { return f.get(); } catch (ExecutionException eex) { ee = eex; } catch (RuntimeException rex) { ee = new ExecutionException(rex); } } }
if (ee == null) ee = new ExecutionException(); throw ee;
} finally { for (int i = 0, size = futures.size(); i < size; i++) futures.get(i).cancel(true); } }
public <T> T invokeAny(Collection<? extends Callable<T>> tasks, long timeout, TimeUnit unit) throws InterruptedException, ExecutionException, TimeoutException { return doInvokeAny(tasks, true, unit.toNanos(timeout)); }
public <T> List<Future<T>> invokeAll(Collection<? extends Callable<T>> tasks) throws InterruptedException { if (tasks == null) throw new NullPointerException(); ArrayList<Future<T>> futures = new ArrayList<Future<T>>(tasks.size()); boolean done = false; try { for (Callable<T> t : tasks) { RunnableFuture<T> f = newTaskFor(t); futures.add(f); execute(f); } for (int i = 0, size = futures.size(); i < size; i++) { Future<T> f = futures.get(i); if (!f.isDone()) { try { f.get(); } catch (CancellationException ignore) { } catch (ExecutionException ignore) { } } } done = true; return futures; } finally { if (!done) for (int i = 0, size = futures.size(); i < size; i++) futures.get(i).cancel(true); } }
public <T> List<Future<T>> invokeAll(Collection<? extends Callable<T>> tasks, long timeout, TimeUnit unit) throws InterruptedException { if (tasks == null) throw new NullPointerException(); long nanos = unit.toNanos(timeout); ArrayList<Future<T>> futures = new ArrayList<Future<T>>(tasks.size()); boolean done = false; try { for (Callable<T> t : tasks) futures.add(newTaskFor(t));
final long deadline = System.nanoTime() + nanos; final int size = futures.size();
// Interleave time checks and calls to execute in case // executor doesn't have any/much parallelism. for (int i = 0; i < size; i++) { execute((Runnable)futures.get(i)); nanos = deadline - System.nanoTime(); if (nanos <= 0L) return futures; }
for (int i = 0; i < size; i++) { Future<T> f = futures.get(i); if (!f.isDone()) { if (nanos <= 0L) return futures; try { f.get(nanos, TimeUnit.NANOSECONDS); } catch (CancellationException ignore) { } catch (ExecutionException ignore) { } catch (TimeoutException toe) { return futures; } nanos = deadline - System.nanoTime(); } } done = true; return futures; } finally { if (!done) for (int i = 0, size = futures.size(); i < size; i++) futures.get(i).cancel(true); } } }
public class ForkJoinPool extends AbstractExecutorService { // 属性方法.. }
ForkJoinPool比较适合计算密集型的任务,以后有机会用到的话再写。
构造器参数
在ThreadPoolExecutor类中有4个构造器,但最终调用的是如下这个构造器:
1 2 3 4 5 6 7
public ThreadPoolExecutor(int corePoolSize, int maximumPoolSize, long keepAliveTime, TimeUnit unit, BlockingQueue<Runnable> workQueue, ThreadFactory threadFactory, RejectedExecutionHandler handler)